- 1 Introduction
- 1.1 The Need for Efficiency
- 1.2 Interfaces
- 1.2.1 The
Queue,Stack, andDequeInterfaces - 1.2.2 The
ListInterface: Linear Sequences - 1.2.3 The
USetInterface: Unordered Sets - 1.2.4 The
SSetInterface: Sorted Sets - 1.3 Mathematical Background
- 1.3.1 Exponentials and Logarithms
- 1.3.2 Factorials
- 1.3.3 Asymptotic Notation
- 1.3.4 Randomization and Probability
- 1.4 The Model of Computation
- 1.5 Correctness, Time Complexity, and Space Complexity
- 1.6 Code Samples
- 1.7 List of Data Structures
- 1.8 Discussion and Exercises
Every computer science curriculum in the world includes a course on data structures and algorithms. Data structures are that important; they improve our quality of life and even save lives on a regular basis. Many multi-million and several multi-billion dollar companies have been built around data structures.
How can this be? If we stop to think about it, we realize that we interact with data structures constantly.
- Open a file: File system data structures are used to locate the parts of that file on disk so they can be retrieved. This isn't easy; disks contain hundreds of millions of blocks. The contents of your file could be stored on any one of them.
- Look up a contact on your phone: A data structure is used to look up a phone number in your contact list based on partial information even before you finish dialing/typing. This isn't easy; your phone may contain information about a lot of people—everyone you have ever contacted via phone or email—and your phone doesn't have a very fast processor or a lot of memory.
- Log in to your favourite social network: The network servers use your login information to look up your account information. This isn't easy; the most popular social networks have hundreds of millions of active users.
- Do a web search: The search engine uses data structures to find the web pages containing your search terms. This isn't easy; there are over 8.5 billion web pages on the Internet and each page contains a lot of potential search terms.
- Phone emergency services (9-1-1): The emergency services network looks up your phone number in a data structure that maps phone numbers to addresses so that police cars, ambulances, or fire trucks can be sent there without delay. This is important; the person making the call may not be able to provide the exact address they are calling from and a delay can mean the difference between life or death.
1.1 The Need for Efficiency
In the next section, we look at the operations supported by the most commonly used data structures. Anyone with a bit of programming experience will see that these operations are not hard to implement correctly. We can store the data in an array or a linked list and each operation can be implemented by iterating over all the elements of the array or list and possibly adding or removing an element.
This kind of implementation is easy, but not very efficient. Does this really matter? Computers are becoming faster and faster. Maybe the obvious implementation is good enough. Let's do some rough calculations to find out.
n, in the data structure
and the number of operations, \(m\), performed on the data structure
are both large. In these cases, the time (measured in, say, machine
instructions) is roughly \(\texttt{n}\times m\).
The solution, of course, is to carefully organize data within the data structure so that not every operation requires every data item to be inspected. Although it sounds impossible at first, we will see data structures where a search requires looking at only two items on average, independent of the number of items stored in the data structure. In our billion instruction per second computer it takes only \(0.000000002\) seconds to search in a data structure containing a billion items (or a trillion, or a quadrillion, or even a quintillion items).
We will also see implementations of data structures that keep the items in sorted order, where the number of items inspected during an operation grows very slowly as a function of the number of items in the data structure. For example, we can maintain a sorted set of one billion items while inspecting at most 60 items during any operation. In our billion instruction per second computer, these operations take \(0.00000006\) seconds each.
The remainder of this chapter briefly reviews some of the main concepts used throughout the rest of the book. Section 1.2 describes the interfaces implemented by all of the data structures described in this book and should be considered required reading. The remaining sections discuss:
- some mathematical review including exponentials, logarithms, factorials, asymptotic (big-Oh) notation, probability, and randomization;
- the model of computation;
- correctness, running time, and space;
- an overview of the rest of the chapters; and
- the sample code and typesetting conventions.
1.2 Interfaces
When discussing data structures, it is important to understand the difference between a data structure's interface and its implementation. An interface describes what a data structure does, while an implementation describes how the data structure does it.An interface, sometimes also called an abstract data type, defines the set of operations supported by a data structure and the semantics, or meaning, of those operations. An interface tells us nothing about how the data structure implements these operations; it only provides a list of supported operations along with specifications about what types of arguments each operation accepts and the value returned by each operation.
A data structure implementation, on the other hand, includes the
internal representation of the data structure as well as the definitions
of the algorithms that implement the operations supported by the data
structure. Thus, there can be many implementations of a single interface.
For example, in Chapter 2, we will see implementations of the
List interface using arrays and in Chapter 3 we will
see implementations of the List interface using pointer-based data
structures. Each implements the same interface, List,
but in different ways.
1.2.1 The Queue, Stack, and Deque Interfaces
The Queue interface represents a collection of elements to which we
can add elements and remove the next element. More precisely, the operations
supported by the Queue interface are
add(x): add the valuexto theQueueremove(): remove the next (previously added) value,y, from theQueueand returny
remove() operation takes no argument. The Queue's
queueing discipline decides which element should be removed.
There are many possible queueing disciplines, the most common of which
include FIFO, priority, and LIFO.
A FIFO (first-in-first-out) Queue,
which is illustrated in
Figure 1.1, removes items in the same order they were added, much
in the same way a queue (or line-up) works when checking out at a cash
register in a grocery store. This is the most common kind of Queue
so the qualifier FIFO is often omitted. In other texts, the add(x)
and remove() operations on a FIFO Queue are often called enqueue(x)
and dequeue(), respectively.

Queue.
A priority Queue,
illustrated in Figure 1.2, always
removes the smallest element from the Queue, breaking ties arbitrarily.
This is similar to the way in which patients are triaged in a hospital
emergency room. As patients arrive they are evaluated and then placed in
a waiting room. When a doctor becomes available he or she first treats
the patient with the most life-threatening condition. The remove()
operation on a priority Queue is usually called deleteMin() in
other texts.

Queue.
A very common queueing discipline is the LIFO (last-in-first-out)
discipline, illustrated in Figure 1.3. In a LIFO Queue,
the most recently added element is the next one removed. This is best
visualized in terms of a stack of plates; plates are placed on the top of
the stack and also removed from the top of the stack. This structure is
so common that it gets its own name: Stack. Often, when discussing a
Stack, the names of add(x) and remove() are changed to push(x)
and pop(); this is to avoid confusing the LIFO and FIFO queueing
disciplines.

A Deque
is a generalization of both the FIFO Queue and LIFO Queue (Stack).
A Deque represents a sequence of elements, with a front and a back.
Elements can be added at the front of the sequence or the back of the
sequence. The names of the Deque operations are self-explanatory:
addFirst(x), removeFirst(), addLast(x), and removeLast(). It is
worth noting that a Stack can be implemented using only addFirst(x)
and removeFirst() while a FIFO Queue can be implemented using
addLast(x) and removeFirst().
1.2.2 The List Interface: Linear Sequences
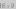
This book will talk very little about the FIFO Queue, Stack, or
Deque interfaces. This is because these interfaces are subsumed by the
List interface. A List,
illustrated in Figure 1.4, represents a
sequence, \(\texttt{x}_0,\ldots,\texttt{x}_{\texttt{n}-1}\), of values. The List interface
includes the following operations:
size(): returnn, the length of the listget(i): return the value \(\texttt{x}_{\texttt{i}}\)set(i,x): set the value of \(\texttt{x}_{\texttt{i}}\) equal toxadd(i,x): addxat positioni, displacing \(\texttt{x}_{\texttt{i}},\ldots,\texttt{x}_{\texttt{n}-1}\);
Set \(\texttt{x}_{j+1}=\texttt{x}_j\), for all \(j\in\{\texttt{n}-1,\ldots,\texttt{i}\}\), incrementn, and set \(\texttt{x}_i=\texttt{x}\)remove(i)remove the value \(\texttt{x}_{\texttt{i}}\), displacing \(\texttt{x}_{\texttt{i+1}},\ldots,\texttt{x}_{\texttt{n}-1}\);
Set \(\texttt{x}_{j}=\texttt{x}_{j+1}\), for all \(j\in\{\texttt{i},\ldots,\texttt{n}-2\}\) and decrementn
Deque interface:
\begin{eqnarray*}
\texttt{addFirst(x)} &\Rightarrow& \texttt{add(0,x)} \\\texttt{removeFirst()} &\Rightarrow& \texttt{remove(0)} \\
\texttt{addLast(x)} &\Rightarrow& \texttt{add(size(),x)} \\
\texttt{removeLast()} &\Rightarrow& \texttt{remove(size()-1)} \end{eqnarray*}

List represents a sequence indexed by
\(0,1,2,\ldots,\texttt{n}-1\). In this List a call to get(2) would return
the value \(c\).
Although we will normally not discuss the Stack, Deque and FIFO
Queue interfaces in subsequent chapters, the terms Stack and Deque
are sometimes used in the names of data structures that implement the
List interface. When this happens, it highlights the fact that
these data structures can be used to implement the Stack or Deque
interface very efficiently. For example, the ArrayDeque class is an
implementation of the List interface that implements all the Deque
operations in constant time per operation.
1.2.3 The USet Interface: Unordered Sets
The USet
interface represents an unordered set of unique elements, which
mimics a mathematical set. A USet contains n distinct
elements; no element appears more than once; the elements are in no
specific order. A USet supports the following operations:
size(): return the number,n, of elements in the setadd(x): add the elementxto the set if not already present;
Addxto the set provided that there is no elementyin the set such thatxequalsy. Returntrueifxwas added to the set andfalseotherwise.remove(x): removexfrom the set;
Find an elementyin the set such thatxequalsyand removey. Returny, ornullif no such element exists.find(x): findxin the set if it exists;
Find an elementyin the set such thatyequalsx. Returny, ornullif no such element exists.
These definitions are a bit fussy about distinguishing x, the element
we are removing or finding, from y, the element we may remove or find.
This is because x and y might actually be distinct objects that
are nevertheless treated as equal.2In Java, this is
done by overriding the class's equals(y) and hashCode() methods.
Such a distinction is useful because it allows for the creation of
dictionaries or maps that map keys onto values.
To create a dictionary/map, one forms compound objects called Pairs,
each of which contains a key and a value. Two Pairs
are treated as equal if their keys are equal. If we store some pair
\((\texttt{k},\texttt{v})\) in a USet and then later call the find(x) method using
the pair \(\texttt{x}=(\texttt{k},\texttt{null})\) the result will be \(\texttt{y}=(\texttt{k},\texttt{v})\). In other
words, it is possible to recover the value, v, given only the key, k.
1.2.4 The SSet Interface: Sorted Sets
The SSet interface represents a sorted set of elements. An SSet
stores elements from some total order, so that any two elements x
and y can be compared. In code examples, this will be done with a
method called compare(x,y) in which
\begin{equation*}
\texttt{compare(x,y)}
\begin{cases}<0 & \text{if \(\texttt{x}<\texttt{y}\)} \\
>0 & \text{if \(\texttt{x}>\texttt{y}\)} \\
=0 & \text{if \(\texttt{x}=\texttt{y}\)}
\end{cases}
\end{equation*}
An SSet supports the size(), add(x), and remove(x) methods with
exactly the same semantics as in the USet interface. The difference
between a USet and an SSet is in the find(x) method:
find(x): locatexin the sorted set;
Find the smallest elementyin the set such that \(\texttt{y} \ge \texttt{x}\). Returnyornullif no such element exists.
This version of the find(x) operation is sometimes referred to
as a successor search.
It differs in a fundamental way from
USet.find(x) since it returns a meaningful result even when there is
no element equal to x in the set.
The distinction between the USet and SSet find(x) operations is
very important and often missed. The extra functionality provided
by an SSet usually comes with a price that includes both a larger
running time and a higher implementation complexity. For example, most
of the SSet implementations discussed in this book all have find(x)
operations with running times that are logarithmic in the size of the set.
On the other hand, the implementation of a USet as a ChainedHashTable
in Chapter 5 has a find(x) operation that runs in constant
expected time. When choosing which of these structures to use, one should
always use a USet unless the extra functionality offered by an SSet
is truly needed.
1.3 Mathematical Background
In this section, we review some mathematical notations and tools used throughout this book, including logarithms, big-Oh notation, and probability theory. This review will be brief and is not intended as an introduction. Readers who feel they are missing this background are encouraged to read, and do exercises from, the appropriate sections of the very good (and free) textbook on mathematics for computer science [50].
1.3.1 Exponentials and Logarithms
The expression \(b^x\) denotes the number \(b\) raised to the power of \(x\). If \(x\) is a positive integer, then this is just the value of \(b\) multiplied by itself \(x-1\) times: \begin{equation*} b^x = \underbrace{b\times b\times \cdots \times b}_{x} \enspace . \end{equation*} When \(x\) is a negative integer, \(b^{-x}=1/b^{x}\). When \(x=0\), \(b^x=1\). When \(b\) is not an integer, we can still define exponentiation in terms of the exponential function \(e^x\) (see below), which is itself defined in terms of the exponential series, but this is best left to a calculus text.
In this book, the expression \(\log_b k\) denotes the base-\(b\) logarithm of \(k\). That is, the unique value \(x\) that satisfies \begin{equation*} b^{x} = k \enspace . \end{equation*} Most of the logarithms in this book are base 2 (binary logarithms). For these, we omit the base, so that \(\log k\) is shorthand for \(\log_2 k\).
An informal, but useful, way to think about logarithms is to think of \(\log_b k\) as the number of times we have to divide \(k\) by \(b\) before the result is less than or equal to 1. For example, when one does binary search, each comparison reduces the number of possible answers by a factor of 2. This is repeated until there is at most one possible answer. Therefore, the number of comparison done by binary search when there are initially at most \(n+1\) possible answers is at most \(\lceil\log_2(n+1)\rceil\).
Another logarithm that comes up several times in this book is the natural logarithm. Here we use the notation \(\ln k\) to denote \(\log_e k\), where \(e\) — Euler's constant — is given by \begin{equation*} e = \lim_{n\rightarrow\infty} \left(1+\frac{1}{n}\right)^n \approx 2.71828 \enspace . \end{equation*} The natural logarithm comes up frequently because it is the value of a particularly common integral: \begin{equation*} \int_{1}^{k} 1/x \mathrm{d}x = \ln k \enspace . \end{equation*} Two of the most common manipulations we do with logarithms are removing them from an exponent: \begin{equation*} b^{\log_b k} = k \end{equation*} and changing the base of a logarithm: \begin{equation*} \log_b k = \frac{\log_a k}{\log_a b} \enspace . \end{equation*} For example, we can use these two manipulations to compare the natural and binary logarithms \begin{equation*} \ln k = \frac{\log k}{\log e} = \frac{\log k}{(\ln e)/(\ln 2)} = (\ln 2)(\log k) \approx 0.693147\log k \enspace . \end{equation*}
1.3.2 Factorials
In one or two places in this book, the factorial function is used. For a non-negative integer \(n\), the notation \(n!\) (pronounced “\(n\) factorial”) is defined to mean \begin{equation*} n! = 1\cdot2\cdot3\cdot\cdots\cdot n \enspace . \end{equation*} Factorials appear because \(n!\) counts the number of distinct permutations, i.e., orderings, of \(n\) distinct elements. For the special case \(n=0\), \(0!\) is defined as 1.
The quantity \(n!\) can be approximated using Stirling's Approximation: \begin{equation*} n! = \sqrt{2\pi n}\left(\frac{n}{e}\right)^{n}e^{\alpha(n)} \enspace , \end{equation*} where \begin{equation*} \frac{1}{12n+1} < \alpha(n) < \frac{1}{12n} \enspace . \end{equation*} Stirling's Approximation also approximates \(\ln(n!)\): \begin{equation*} \ln(n!) = n\ln n - n + \frac{1}{2}\ln(2\pi n) + \alpha(n) \end{equation*} (In fact, Stirling's Approximation is most easily proven by approximating \(\ln(n!)=\ln 1 + \ln 2 + \cdots + \ln n\) by the integral \(\int_1^n \ln n \mathrm{d}n = n\ln n - n +1\).)
Related to the factorial function are the binomial coefficients. For a non-negative integer \(n\) and an integer \(k\in\{0,\ldots,n\}\), the notation \(\binom{n}{k}\) denotes: \begin{equation*} \binom{n}{k} = \frac{n!}{k!(n-k)!} \enspace . \end{equation*} The binomial coefficient \(\binom{n}{k}\) (pronounced “\(n\) choose \(k\)”) counts the number of subsets of an \(n\) element set that have size \(k\), i.e., the number of ways of choosing \(k\) distinct integers from the set \(\{1,\ldots,n\}\).
1.3.3 Asymptotic Notation
When analyzing data structures in this book, we want to talk about
the running times of various operations. The exact running times will,
of course, vary from computer to computer and even from run to run on an
individual computer. When we talk about the running time of an operation
we are referring to the number of computer instructions performed during
the operation. Even for simple code, this quantity can be difficult to
compute exactly. Therefore, instead of analyzing running times exactly,
we will use the so-called big-Oh notation: For a function \(f(n)\),
\(O(f(n))\) denotes a set of functions,
\begin{equation*}
O(f(n)) = \left\{
\begin{array}
g(n):\mbox{there exists \(c>0\), and \(n_0\) such that} \\
\quad\mbox{\(g(n) \le c\cdot f(n)\) for all \(n\ge n_0\)}
\end{array} \right\} \enspace .
\end{equation*}
Thinking graphically, this set consists of the functions \(g(n)\) where
\(c\cdot f(n)\) starts to dominate \(g(n)\) when \(n\) is sufficiently large.
We generally use asymptotic notation to simplify functions. For example,
in place of \(5n\log n + 8n - 200\) we can write \(O(n\log n)\).
This is proven as follows:
\begin{align*}
5n\log n + 8n - 200
& \le 5n\log n + 8n \\
& \le 5n\log n + 8n\log n & \mbox{ for \(n\ge 2\) (so that \(\log n \ge 1\))}
\\
& \le 13n\log n \enspace .
\end{align*}
This demonstrates that the function \(f(n)=5n\log n + 8n - 200\) is in
the set \(O(n\log n)\) using the constants \(c=13\) and \(n_0 = 2\).
A number of useful shortcuts can be applied when using asymptotic notation. First: \begin{equation*} O(n^{c_1}) \subset O(n^{c_2}) \enspace ,\end{equation*} for any \(c_1 < c_2\). Second: For any constants \(a,b,c > 0\), \begin{equation*} O(a) \subset O(\log n) \subset O(n^{b}) \subset O({c}^n) \enspace . \end{equation*} These inclusion relations can be multiplied by any positive value, and they still hold. For example, multiplying by \(n\) yields: \begin{equation*} O(n) \subset O(n\log n) \subset O(n^{1+b}) \subset O(n{c}^n) \enspace . \end{equation*}
Continuing in a long and distinguished tradition, we will abuse this notation by writing things like \(f_1(n) = O(f(n))\) when what we really mean is \(f_1(n) \in O(f(n))\). We will also make statements like “the running time of this operation is \(O(f(n))\)” when this statement should be “the running time of this operation is a member of \(O(f(n))\).” These shortcuts are mainly to avoid awkward language and to make it easier to use asymptotic notation within strings of equations.
A particularly strange example of this occurs when we write statements like \begin{equation*} T(n) = 2\log n + O(1) \enspace . \end{equation*} Again, this would be more correctly written as \begin{equation*} T(n) \le 2\log n + [\mbox{some member of \(O(1)\)]} \enspace . \end{equation*}
The expression \(O(1)\) also brings up another issue. Since there is no variable in this expression, it may not be clear which variable is getting arbitrarily large. Without context, there is no way to tell. In the example above, since the only variable in the rest of the equation is \(n\), we can assume that this should be read as \(T(n) = 2\log n + O(f(n))\), where \(f(n) = 1\).
Big-Oh notation is not new or unique to computer science. It was used by the number theorist Paul Bachmann as early as 1894, and is immensely useful for describing the running times of computer algorithms. Consider the following piece of code:
void snippet() {
for (int i = 0; i < n; i++)
a[i] = i;
}
- \(1\) assignment (
int\, i\, =\, 0), - \(\texttt{n}+1\) comparisons (
i < n), nincrements (i++),narray offset calculations (a[i]), andnindirect assignments (a[i] = i).
Big-Oh notation allows us to reason at a much higher level, making
it possible to analyze more complicated functions. If two algorithms
have the same big-Oh running time, then we won't know which is faster,
and there may not be a clear winner. One may be faster on one machine,
and the other may be faster on a different machine. However, if the
two algorithms have demonstrably different big-Oh running times, then
we can be certain that the one with the smaller running time will be
faster for large enough values of n.
An example of how big-Oh notation allows us to compare two different
functions is shown in Figure 1.5, which compares the rate
of growth of \(f_1(\texttt{n})=15\texttt{n}\) versus \(f_2(n)=2\texttt{n}\log\texttt{n}\). It might be
that \(f_1(n)\) is the running time of a complicated linear time algorithm
while \(f_2(n)\) is the running time of a considerably simpler algorithm
based on the divide-and-conquer paradigm. This illustrates that,
although \(f_1(\texttt{n})\) is greater than \(f_2(n)\) for small values of n,
the opposite is true for large values of n. Eventually \(f_1(\texttt{n})\)
wins out, by an increasingly wide margin. Analysis using big-Oh notation
told us that this would happen, since \(O(\texttt{n})\subset O(\texttt{n}\log \texttt{n})\).
In a few cases, we will use asymptotic notation on functions with more
than one variable. There seems to be no standard for this, but for our
purposes, the following definition is sufficient:
\begin{equation*}
O(f(n_1,\ldots,n_k)) =
\left\{\begin{array}
g(n_1,\ldots,n_k):\mbox{there exists \(c>0\), and \(z\) such that} \\
\quad \mbox{\(g(n_1,\ldots,n_k) \le c\cdot f(n_1,\ldots,n_k)\)} \\
\qquad \mbox{for all \(n_1,\ldots,n_k\) such that \(g(n_1,\ldots,n_k)\ge z\)}
\end{array}\right\} \enspace .
\end{equation*}
This definition captures the situation we really care about: when the
arguments \(n_1,\ldots,n_k\) make \(g\) take on large values. This definition
also agrees with the univariate definition of \(O(f(n))\) when \(f(n)\)
is an increasing function of \(n\). The reader should be warned that,
although this works for our purposes, other texts may treat multivariate
functions and asymptotic notation differently.
1.3.4 Randomization and Probability
Some of the data structures presented in this book are randomized; they make random choices that are independent of the data being stored in them or the operations being performed on them. For this reason, performing the same set of operations more than once using these structures could result in different running times. When analyzing these data structures we are interested in their average or expected running times.
Formally, the running time of an operation on a randomized data structure is a random variable, and we want to study its expected value. For a discrete random variable \(X\) taking on values in some countable universe \(U\), the expected value of \(X\), denoted by \(\E[X]\), is given by the formula \begin{equation*} \E[X] = \sum_{x\in U} x\cdot\Pr\{X=x\} \enspace . \end{equation*} Here \(\Pr\{\mathcal{E}\}\) denotes the probability that the event \(\mathcal{E}\) occurs. In all of the examples in this book, these probabilities are only with respect to the random choices made by the randomized data structure; there is no assumption that the data stored in the structure, nor the sequence of operations performed on the data structure, is random.
One of the most important properties of expected values is linearity of expectation. For any two random variables \(X\) and \(Y\), \begin{equation*} \E[X+Y] = \E[X] + \E[Y] \enspace . \end{equation*} More generally, for any random variables \(X_1,\ldots,X_k\), \begin{equation*} \E\left[\sum_{i=1}^k X_i\right] = \sum_{i=1}^k \E[X_i] \enspace . \end{equation*} Linearity of expectation allows us to break down complicated random variables (like the left hand sides of the above equations) into sums of simpler random variables (the right hand sides).
A useful trick, that we will use repeatedly, is defining indicator
random variables.
These binary variables are useful when we want to
count something and are best illustrated by an example. Suppose we toss
a fair coin \(k\) times and we want to know the expected number of times
the coin turns up as heads.
Intuitively, we know the answer is \(k/2\),
but if we try to prove it using the definition of expected value, we get
\begin{align*}
\E[X] & = \sum_{i=0}^k i\cdot\Pr\{X=i\} \\
& = \sum_{i=0}^k i\cdot\binom{k}{i}/2^k \\
& = k\cdot \sum_{i=0}^{k-1}\binom{k-1}{i}/2^k \\
& = k/2 \enspace .
\end{align*}
This requires that we know enough to calculate that \(\Pr\{X=i\}
= \binom{k}{i}/2^k\), and that we know the binomial identities
\(i\binom{k}{i}=k\binom{k-1}{i-1}\) and \(\sum_{i=0}^{k} \binom{k}{i} = 2^{k}\).
Using indicator variables and linearity of expectation makes things
much easier. For each \(i\in\{1,\ldots,k\}\), define the indicator
random variable
\begin{equation*}
I_i = \begin{cases}
1 & \text{if the \(i\)th coin toss is heads} \\
0 & \text{otherwise.}
\end{cases}
\end{equation*}
Then
\begin{equation*} \E[I_i] = (1/2)1 + (1/2)0 = 1/2 \enspace . \end{equation*}
Now, \(X=\sum_{i=1}^k I_i\), so
\begin{align*}
\E[X] & = \E\left[\sum_{i=1}^k I_i\right] \\
& = \sum_{i=1}^k \E[I_i] \\
& = \sum_{i=1}^k 1/2 \\
& = k/2 \enspace .
\end{align*}
This is a bit more long-winded, but doesn't require that we know any
magical identities or compute any non-trivial probabilities. Even better,
it agrees with the intuition that we expect half the coins to turn up as
heads precisely because each individual coin turns up as heads with
a probability of \(1/2\).
1.4 The Model of Computation
In this book, we will analyze the theoretical running times of operations
on the data structures we study. To do this precisely, we need a
mathematical model of computation. For this, we use the w-bit
word-RAM
model. RAM stands for Random Access Machine. In this model, we
have access to a random access memory consisting of cells, each of
which stores a w-bit word.
This implies that a memory cell can
represent, for example, any integer in the set \(\{0,\ldots,2^{\texttt{w}}-1\}\).
In the word-RAM model, basic operations on words take constant time.
This includes arithmetic operations (+, -, *, /, %), comparisons
(\(<\), \(>\), \(=\), \(\le\), \(\ge\)), and bitwise boolean operations (bitwise-AND,
OR, and exclusive-OR).
Any cell can be read or written in constant time. A computer's memory is managed by a memory management system from which we can allocate or deallocate a block of memory of any size we would like. Allocating a block of memory of size \(k\) takes \(O(k)\) time and returns a reference (a pointer) to the newly-allocated memory block. This reference is small enough to be represented by a single word.
The word-size w is a very important parameter of this model. The only
assumption we will make about w is the lower-bound \(\texttt{w} \ge \log \texttt{n}\),
where n is the number of elements stored in any of our data structures.
This is a fairly modest assumption, since otherwise a word is not even
big enough to count the number of elements stored in the data structure.
Space is measured in words, so that when we talk about the amount of
space used by a data structure, we are referring to the number of words
of memory used by the structure. All of our data structures store values of
a generic type T, and we assume an element of type T occupies one word
of memory. (In reality, we are storing references to objects
of type T, and these references occupy only one word of memory.)
The w-bit word-RAM model is a fairly close match for the
(32-bit) Java Virtual Machine (JVM) when \(\texttt{w}=32\). The data structures presented in this book don't
use any special tricks that are not implementable on the JVM and most
other architectures.
1.5 Correctness, Time Complexity, and Space Complexity
When studying the performance of a data structure, there are three things that matter most:
- Correctness: The data structure should correctly implement its interface.
- Time complexity: The running times of operations on the data structure should be as small as possible.
- Space complexity: The data structure should use as little memory as possible.
In this introductory text, we will take correctness as a given; we won't consider data structures that give incorrect answers to queries or don't perform updates properly. We will, however, see data structures that make an extra effort to keep space usage to a minimum. This won't usually affect the (asymptotic) running times of operations, but can make the data structures a little slower in practice.
When studying running times in the context of data structures we tend to come across three different kinds of running time guarantees:
- Worst-case running times: These are the strongest kind of running time guarantees. If a data structure operation has a worst-case running time of \(f(\texttt{n})\), then one of these operations never takes longer than \(f(\texttt{n})\) time.
- Amortized running times: If we say that the amortized running time of an operation in a data structure is \(f(\texttt{n})\), then this means that the cost of a typical operation is at most \(f(\texttt{n})\). More precisely, if a data structure has an amortized running time of \(f(\texttt{n})\), then a sequence of \(m\) operations takes at most \(mf(\texttt{n})\) time. Some individual operations may take more than \(f(\texttt{n})\) time but the average, over the entire sequence of operations, is at most \(f(\texttt{n})\).
- Expected running times: If we say that the expected running time of an operation on a data structure is \(f(\texttt{n})\), this means that the actual running time is a random variable (see Section 1.3.4) and the expected value of this random variable is at most \(f(\texttt{n})\). The randomization here is with respect to random choices made by the data structure.
To understand the difference between worst-case, amortized, and expected running times, it helps to consider a financial example. Consider the cost of buying a house:
If we have enough cash on hand, we might choose to buy the house outright, with one payment of $120 000. In this case, over a period of 10 years, the amortized monthly cost of buying this house is \begin{equation*} $120 000 / 120\text{ months} = $1 000\text{ per month} \enspace . \end{equation*} This is much less than the $1 200 per month we would have to pay if we took out a mortgage.
Now it's decision time. Should we pay the $15 worst-case monthly cost for fire insurance, or should we gamble and self-insure at an expected cost of $10 per month? Clearly, the $10 per month costs less in expectation, but we have to be able to accept the possibility that the actual cost may be much higher. In the unlikely event that the entire house burns down, the actual cost will be $120 000.
These financial examples also offer insight into why we sometimes settle for an amortized or expected running time over a worst-case running time. It is often possible to get a lower expected or amortized running time than a worst-case running time. At the very least, it is very often possible to get a much simpler data structure if one is willing to settle for amortized or expected running times.
1.6 Code Samples
The code samples in this book are written in the Java programming
language. However, to make the book accessible to readers not familiar
with all of Java's constructs and keywords, the code samples have
been simplified. For example, a reader won't find any of the keywords
public, protected, private, or static. A reader also won't find
much discussion about class hierarchies. Which interfaces a particular
class implements or which class it extends, if relevant to the discussion,
should be clear from the accompanying text.
These conventions should make the code samples understandable by anyone with a background in any of the languages from the ALGOL tradition, including B, C, C++, C#, Objective-C, D, Java, JavaScript, and so on. Readers who want the full details of all implementations are encouraged to look at the Java source code that accompanies this book.
This book mixes mathematical analyses of running times with Java source code for the algorithms being analyzed. This means that
some equations contain variables also found in the source code.
These variables are typeset consistently, both within the source code
and within equations. The most common such variable is the variable n
that, without exception, always refers to the number of items currently
stored in the data structure.
1.7 List of Data Structures
Tables Table 1.5 and Table 1.5 summarize the
performance of data structures in this book that implement each of the
interfaces, List, USet, and SSet, described in Section 1.2.
Figure 1.6 shows the dependencies between various chapters in
this book.
A dashed arrow indicates only a weak dependency, in which
only a small part of the chapter depends on a previous chapter or only
the main results of the previous chapter.
List and USet implementations.
find(x) | add(x)/remove(x) | ||
SkiplistSSet | \(O(\log \texttt{n})\)E | \(O(\log \texttt{n})\)E | Section 4.2 |
Treap | \(O(\log \texttt{n})\)E | \(O(\log \texttt{n})\)E | Section 7.2 |
ScapegoatTree | \(O(\log \texttt{n})\) | \(O(\log \texttt{n})\)A | Section 8.1 |
RedBlackTree | \(O(\log \texttt{n})\) | \(O(\log \texttt{n})\) | Section 9.2 |
BinaryTrieI | \(O(\texttt{w})\) | \(O(\texttt{w})\) | Section 13.1 |
XFastTrieI | \(O(\log \texttt{w})\)A,E | \(O(\texttt{w})\)A,E | Section 13.2 |
YFastTrieI | \(O(\log \texttt{w})\)A,E | \(O(\log \texttt{w})\)A,E | Section 13.3 |
BTree | \(O(\log \texttt{n})\) | \(O(B+\log \texttt{n})\)A | Section 14.2 |
BTreeX | \(O(\log_B \texttt{n})\) | \(O(\log_B \texttt{n})\) | Section 14.2 |
| [2ex] | |||
findMin() | add(x)/remove() | ||
BinaryHeap | \(O(1)\) | \(O(\log \texttt{n})\)A | Section 10.1 |
MeldableHeap | \(O(1)\) | \(O(\log \texttt{n})\)E | Section 10.2 |
- I
- X
SSet and priority Queue implementations.
1.8 Discussion and Exercises
The List, USet, and SSet interfaces described in
Section 1.2 are influenced by the Java Collections Framework
[54].
These are essentially simplified versions of
the List, Set, Map, SortedSet, and SortedMap interfaces found in
the Java Collections Framework. The accompanying source
code includes wrapper classes for making USet and SSet implementations
into Set, Map, SortedSet, and SortedMap implementations.
For a superb (and free) treatment of the mathematics discussed in this chapter, including asymptotic notation, logarithms, factorials, Stirling's approximation, basic probability, and lots more, see the textbook by Leyman, Leighton, and Meyer [50]. For a gentle calculus text that includes formal definitions of exponentials and logarithms, see the (freely available) classic text by Thompson [73].
For more information on basic probability, especially as it relates to computer science, see the textbook by Ross [65]. Another good reference, which covers both asymptotic notation and probability, is the textbook by Graham, Knuth, and Patashnik [37].
Readers wanting to brush up on their Java programming can find many Java tutorials online [56].
Stack, Queue, Deque, USet, or SSet)
provided by the Java Collections Framework.
Solve the following problems by reading a text file one line at a time and performing operations on each line in the appropriate data structure(s). Your implementations should be fast enough that even files containing a million lines can be processed in a few seconds.
- Read the input one line at a time and then write the lines out in reverse order, so that the last input line is printed first, then the second last input line, and so on.
- Read the first 50 lines of input and then write them out in
reverse order. Read the next 50 lines and then write them out in
reverse order. Do this until there are no more lines left to read,
at which point any remaining lines should be output in reverse
order.
In other words, your output will start with the 50th line, then the 49th, then the 48th, and so on down to the first line. This will be followed by the 100th line, followed by the 99th, and so on down to the 51st line. And so on.
Your code should never have to store more than 50 lines at any given time.
- Read the input one line at a time. At any point after reading the first 42 lines, if some line is blank (i.e., a string of length 0), then output the line that occured 42 lines prior to that one. For example, if Line 242 is blank, then your program should output line 200. This program should be implemented so that it never stores more than 43 lines of the input at any given time.
- Read the input one line at a time and write each line to the output if it is not a duplicate of some previous input line. Take special care so that a file with a lot of duplicate lines does not use more memory than what is required for the number of unique lines.
- Read the input one line at a time and write each line to the output only if you have already read this line before. (The end result is that you remove the first occurrence of each line.) Take special care so that a file with a lot of duplicate lines does not use more memory than what is required for the number of unique lines.
- Read the entire input one line at a time. Then output all lines sorted by length, with the shortest lines first. In the case where two lines have the same length, resolve their order using the usual “sorted order.” Duplicate lines should be printed only once.
- Do the same as the previous question except that duplicate lines should be printed the same number of times that they appear in the input.
- Read the entire input one line at a time and then output the even numbered lines (starting with the first line, line 0) followed by the odd-numbered lines.
- Read the entire input one line at a time and randomly permute the lines before outputting them. To be clear: You should not modify the contents of any line. Instead, the same collection of lines should be printed, but in a random order.
Stack push(x) and pop() operations.
n, you can determine if it is a matched string in \(O(\texttt{n})\)
time.
Stack, s, that supports only the push(x)
and pop() operations. Show how, using only a FIFO Queue, q,
you can reverse the order of all elements in s.
USet, implement a Bag. A Bag is like a USet—it
supports the add(x), remove(x) and find(x) methods—but it allows
duplicate elements to be stored. The find(x) operation in a Bag
returns some element (if any) that is equal to x. In addition,
a Bag supports the findAll(x) operation that returns a list of
all elements in the Bag that are equal to x.
List, USet
and SSet interfaces. These do not have to be efficient. They can
be used later to test the correctness and performance of more efficient
implementations. (The easiest way to do this is to store the elements
in an array.)
add(i,x) and
remove(i) in your List implementation. Think about how you could
improve the performance of the find(x) operation in your USet
and SSet implementations. This exercise is designed to give you a
feel for how difficult it can be to obtain efficient implementations
of these interfaces.