- 5 Hash Tables
Hash tables are an efficient method of storing a small number,
n, of integers from a large range \(U=\{0,\ldots,2^{\texttt{w}}-1\}\).
The term hash table
includes a broad range of data structures. The first part of this
chapter focuses on two of the most common implementations of hash tables:
hashing with chaining and linear probing.
Very often hash tables store types of data that are not integers. In this case, an integer hash code is associated with each data item and is used in the hash table. The second part of this chapter discusses how such hash codes are generated.
Some of the methods used in this chapter require random choices of integers in some specific range. In the code samples, some of these “random” integers are hard-coded constants. These constants were obtained using random bits generated from atmospheric noise.
5.1 ChainedHashTable: Hashing with Chaining
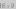
A ChainedHashTable data structure uses hashing with chaining to store
data as an array, t, of lists. An integer, n, keeps track of the
total number of items in all lists (see Figure 5.1):
List<T>[] t;
int n;

ChainedHashTable with \(\texttt{n}=14\) and \(\texttt{t.length}=16\). In this example \(\texttt{hash(x)}=6\)x, denoted hash(x) is a value
in the range \(\{0,\ldots,\texttt{t.length}-1\}\). All items with hash value i
are stored in the list at t[i]. To ensure that lists don't get too
long, we maintain the invariant
\begin{equation*}
\texttt{n} \le \texttt{t.length}
\end{equation*}
so that the average number of elements stored in one of these lists is
\(\texttt{n}/\texttt{t.length} \le 1\).
To add an element, x, to the hash table, we first check if
the length of t needs to be increased and, if so, we grow t.
With this out of the way we hash x to get an integer, i, in the
range \(\{0,\ldots,\texttt{t.length}-1\}\), and we append x to the list
t[i]:
boolean add(T x) {
if (find(x) != null) return false;
if (n+1 > t.length) resize();
t[hash(x)].add(x);
n++;
return true;
}
t and reinserting
all elements into the new table. This strategy is exactly the same
as the one used in the implementation of ArrayStack and the same
result applies: The cost of growing is only constant when amortized
over a sequence of insertions (see Lemma 2.1 on
page X).
Besides growing, the only other work done when adding a new value x to a
ChainedHashTable involves appending x to the list t[hash(x)]. For
any of the list implementations described in Chapters Chapter 2
or Chapter 3, this takes only constant time.
To remove an element, x, from the hash table, we iterate over the list
t[hash(x)] until we find x so that we can remove it:
T remove(T x) {
Iterator<T> it = t[hash(x)].iterator();
while (it.hasNext()) {
T y = it.next();
if (y.equals(x)) {
it.remove();
n--;
return y;
}
}
return null;
}
t[i].
Searching for the element x in a hash table is similar. We perform
a linear search on the list t[hash(x)]:
T find(Object x) {
for (T y : t[hash(x)])
if (y.equals(x))
return y;
return null;
}
t[hash(x)].
The performance of a hash table depends critically on the choice of the
hash function. A good hash function will spread the elements evenly
among the t.length lists, so that the expected size of the list
t[hash(x)] is \(O(\texttt{n}/\texttt{t.length)} = O(1)\). On the other hand, a bad
hash function will hash all values (including x) to the same table
location, in which case the size of the list t[hash(x)] will be n.
In the next section we describe a good hash function.
5.1.1 Multiplicative Hashing
Multiplicative hashing is an efficient method of generating hash values based on modular arithmetic (discussed in Section 2.3) and integer division. It uses the \(\ddiv\) operator, which calculates the integral part of a quotient, while discarding the remainder. Formally, for any integers \(a\ge 0\) and \(b\ge 1\), \(a\ddiv b = \lfloor a/b\rfloor\).
In multiplicative hashing, we use a hash table of size \(2^{\texttt{d}}\) for some
integer d (called the dimension). The formula for hashing an
integer \(\texttt{x}\in\{0,\ldots,2^{\texttt{w}}-1\}\) is
\begin{equation*}
\texttt{hash(x)} = ((\texttt{z}\cdot\texttt{x}) \bmod 2^{\texttt{w}}) \ddiv 2^{\texttt{w}-\texttt{d}} \enspace .
\end{equation*}
Here, z is a randomly chosen odd integer in
\(\{1,\ldots,2^{\texttt{w}}-1\}\). This hash function can be realized very
efficiently by observing that, by default, operations on integers
are already done modulo \(2^{\texttt{w}}\) where \(\texttt{w}\) is the number of bits
in an integer.10This is true for most programming languages
including C, C#, C++, and Java. Notable exceptions are Python and
Ruby, in which the result of a fixed-length w-bit integer operation
that overflows is upgraded to a variable-length representation. (See
Figure 5.2.) Furthermore, integer division by \(2^{\texttt{w}-\texttt{d}}\)
is equivalent to dropping the rightmost \(\texttt{w}-\texttt{d}\) bits in a binary
representation (which is implemented by shifting the bits right by
\(\texttt{w}-\texttt{d}\) using the >>>
operator). In this way, the code that implements the above
formula is simpler than the formula itself:
int hash(Object x) {
return (z * x.hashCode()) >>> (w-d);
}
The following lemma, whose proof is deferred until later in this section, shows that multiplicative hashing does a good job of avoiding collisions:
x and y be any two values in \(\{0,\ldots,2^{\texttt{w}}-1\}\) with
\(\texttt{x}\neq \texttt{y}\). Then \(\Pr\{\texttt{hash(x)}=\texttt{hash(y)}\} \le 2/2^{\texttt{d}}\).
With Lemma 5.1, the performance of remove(x), and
find(x) are easy to analyze:
x, the expected length of the list t[hash(x)]
is at most \(\texttt{n}_{\texttt{x}} + 2\), where \(\texttt{n}_{\texttt{x}}\) is the number of
occurrences of x in the hash table.
x. For an element \(\texttt{y}\in S\), define the indicator
variable
\begin{equation*} I_{\texttt{y}} = \left\{\begin{array}
1 & \mbox{if \(\texttt{hash(x)}=\texttt{hash(y)}\)} \\0 & \mbox{otherwise} \end{array}\right. \end{equation*} and notice that, by Lemma 5.1, \(\E[I_{\texttt{y}}] \le 2/2^{\texttt{d}}=2/\texttt{t.length}\). The expected length of the list
t[hash(x)]
is given by
\begin{eqnarray*}
\E\left[\texttt{t[hash(x)].size()}\right] &=& \E\left[\texttt{n}_{\texttt{x}} + \sum_{\texttt{y}\in S} I_{\texttt{y}}\right] \\&=& \texttt{n}_{\texttt{x}} + \sum_{\texttt{y}\in S} \E[I_{\texttt{y}} ] \\
&\le& \texttt{n}_{\texttt{x}} + \sum_{\texttt{y}\in S} 2/\texttt{t.length} \\
&\le& \texttt{n}_{\texttt{x}} + \sum_{\texttt{y}\in S} 2/\texttt{n} \\
&\le& \texttt{n}_{\texttt{x}} + (\texttt{n}-\texttt{n}_{\texttt{x}})2/\texttt{n} \\
&\le& \texttt{n}_{\texttt{x}} + 2 \enspace , \end{eqnarray*} as required.
Now, we want to prove Lemma 5.1, but first we need a result from number theory. In the following proof, we use the notation \((b_r,\ldots,b_0)_2\) to denote \(\sum_{i=0}^r b_i2^i\), where each \(b_i\) is a bit, either 0 or 1. In other words, \((b_r,\ldots,b_0)_2\) is the integer whose binary representation is given by \(b_r,\ldots,b_0\). We use \(\star\) to denote a bit of unknown value.
Suppose, for the sake of contradiction, that there are two such values
z and z', with \(\texttt{z}>\texttt{z}'\). Then
\begin{equation*}
\texttt{z}q\bmod 2^{\texttt{w}} = \texttt{z}'q \bmod 2^{\texttt{w}} = i
\end{equation*}
So
\begin{equation*}
(\texttt{z}-\texttt{z}')q\bmod 2^{\texttt{w}} = 0
\end{equation*}
But this means that
\begin{equation}
(\texttt{z}-\texttt{z}')q = k 2^{\texttt{w}}
\end{equation}
for some integer \(k\). Thinking in terms of binary numbers, we have
\begin{equation*}
(\texttt{z}-\texttt{z}')q = k\cdot(1,\underbrace{0,\ldots,0}_{\texttt{w}})_2 \enspace ,
\end{equation*}
so that the w trailing bits in the binary representation of
\((\texttt{z}-\texttt{z}')q\) are all 0's.
Furthermore \(k\neq 0\), since \(q\neq 0\) and \(\texttt{z}-\texttt{z}'\neq 0\). Since \(q\)
is odd, it has no trailing 0's in its binary representation:
\begin{equation*}
q = (\star,\ldots,\star,1)_2 \enspace .
\end{equation*}
Since \(|\texttt{z}-\texttt{z}'| < 2^{\texttt{w}}\), \(\texttt{z}-\texttt{z}'\) has fewer than w trailing
0's in its binary representation:
\begin{equation*}
\texttt{z}-\texttt{z}' = (\star,\ldots,\star,1,\underbrace{0,\ldots,0}_{<\texttt{w}})_2
\enspace .
\end{equation*}
Therefore, the product \((\texttt{z}-\texttt{z}')q\) has fewer than w trailing 0's in
its binary representation:
\begin{equation*}
(\texttt{z}-\texttt{z}')q = (\star,\cdots,\star,1,\underbrace{0,\ldots,0}_{<\texttt{w}})_2
\enspace .
\end{equation*}
Therefore \((\texttt{z}-\texttt{z}')q\) cannot satisfy Equation 5.1, yielding a
contradiction and completing the proof.
The utility of Lemma 5.3 comes from the following
observation: If z is chosen uniformly at random from \(S\), then zt
is uniformly distributed over \(S\). In the following proof, it helps
to think of the binary representation of z, which consists of \(\texttt{w}-1\)
random bits followed by a 1.
d bits of \(\texttt{z} \texttt{x}\bmod2^{\texttt{w}}\)
and the highest-order d bits of \(\texttt{z} \texttt{y}\bmod 2^{\texttt{w}}\) are the same.”
A necessary condition of that statement is that the highest-order
d bits in the binary representation of \(\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}}\)
are either all 0's or all 1's. That is,
\begin{equation}
\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}} =
(\underbrace{0,\ldots,0}_{\texttt{d}},\underbrace{\star,\ldots,\star}_{\texttt{w}-\texttt{d}})_2
\end{equation}
when \(\texttt{zx}\bmod 2^{\texttt{w}} > \texttt{zy}\bmod 2^{\texttt{w}}\) or
\begin{equation}
\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}} =
(\underbrace{1,\ldots,1}_{\texttt{d}},\underbrace{\star,\ldots,\star}_{\texttt{w}-\texttt{d}})_2
\enspace .
\end{equation}
when \(\texttt{zx}\bmod 2^{\texttt{w}} < \texttt{zy}\bmod 2^{\texttt{w}}\).
Therefore, we only have to bound the probability that
\(\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}}\) looks like Equation 5.2 or Equation 5.3.
Let \(q\) be the unique odd integer such that \((\texttt{x}-\texttt{y})\bmod
2^{\texttt{w}}=q2^r\) for some integer \(r\ge 0\). By
Lemma 5.3, the binary representation of \(\texttt{z}q\bmod
2^{\texttt{w}}\) has \(\texttt{w}-1\) random bits, followed by a 1:
\begin{equation*}
\texttt{z}q\bmod 2^{\texttt{w}} = (\underbrace{b_{\texttt{w}-1},\ldots,b_{1}}_{\texttt{w}-1},1)_2
\end{equation*}
Therefore, the binary representation of \(\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}}=\texttt{z}q2^r\bmod 2^{\texttt{w}}\) has
\(\texttt{w}-r-1\) random bits, followed by a 1, followed by \(r\) 0's:
\begin{equation*}
\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}} =
\texttt{z}q2^{r}\bmod 2^{\texttt{w}} =
(\underbrace{b_{\texttt{w}-r-1},\ldots,b_{1}}_{\texttt{w}-r-1},1,\underbrace{0,0,\ldots,0}_{r})_2
\end{equation*}
We can now finish the proof: If \(r > \texttt{w}-\texttt{d}\), then the d
higher order bits of \(\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}}\) contain both 0's
and 1's, so the probability that \(\texttt{z}(\texttt{x}-\texttt{y})\bmod 2^{\texttt{w}}\) looks
like Equation 5.2 or Equation 5.3 is 0. If \(\texttt{r}=\texttt{w}-\texttt{d}\),
then the probability of looking like Equation 5.2 is 0, but the
probability of looking like Equation 5.3 is \(1/2^{\texttt{d}-1}=2/2^{\texttt{d}}\)
(since we must have \(b_1,\ldots,b_{d-1}=1,\ldots,1\)). If \(r < \texttt{w}-\texttt{d}\),
then we must have \(b_{\texttt{w}-r-1},\ldots,b_{\texttt{w}-r-\texttt{d}}=0,\ldots,0\) or
\(b_{\texttt{w}-r-1},\ldots,b_{\texttt{w}-r-\texttt{d}}=1,\ldots,1\). The probability of each
of these cases is \(1/2^{\texttt{d}}\) and they are mutually exclusive, so the
probability of either of these cases is \(2/2^{\texttt{d}}\). This completes
the proof.
5.1.2 Summary
The following theorem summarizes the performance of a ChainedHashTable
data structure:
ChainedHashTable implements the USet interface. Ignoring the cost of
calls to grow(), a ChainedHashTable supports the operations add(x),
remove(x), and find(x) in \(O(1)\) expected time per operation.
Furthermore, beginning with an empty ChainedHashTable, any sequence of
\(m\) add(x) and remove(x) operations results in a total of \(O(m)\)
time spent during all calls to grow().
5.2 LinearHashTable: Linear Probing
The ChainedHashTable data structure uses an array of lists, where the ith
list stores all elements x such that \(\texttt{hash(x)}=\texttt{i}\). An alternative,
called open addressing
is to store the elements directly in an
array, t, with each array location in t storing at most one value.
This approach is taken by the LinearHashTable described in this
section. In some places, this data structure is described as open
addressing with linear probing.
The main idea behind a LinearHashTable is that we would, ideally, like
to store the element x with hash value i=hash(x) in the table location
t[i]. If we cannot do this (because some element is already stored
there) then we try to store it at location \(\texttt{t}[(\texttt{i}+1)\bmod\texttt{t.length}]\);
if that's not possible, then we try \(\texttt{t}[(\texttt{i}+2)\bmod\texttt{t.length}]\),
and so on, until we find a place for x.
There are three types of entries stored in t:
- data values: actual values in the
USetthat we are representing; nullvalues: at array locations where no data has ever been stored; anddelvalues: at array locations where data was once stored but that has since been deleted.
n, that keeps track of the number of elements
in the LinearHashTable, a counter, q, keeps track of the number of
elements of Types 1 and 3. That is, q is equal to n plus the number
of del values in t. To make this work efficiently, we need
t to be considerably larger than q, so that there are lots of null
values in t. The operations on a LinearHashTable therefore maintain
the invariant that \(\texttt{t.length}\ge 2\texttt{q}\).
To summarize, a LinearHashTable contains an array, t, that stores
data elements, and integers n and q that keep track of the number of
data elements and non-null values of t, respectively. Because many
hash functions only work for table sizes that are a power of 2, we also
keep an integer d and maintain the invariant that \(\texttt{t.length}=2^\texttt{d}\).
T[] t; // the table
int n; // the size
int q; // number of non-null entries in t
int d; // t.length = 2^d
The find(x) operation in a LinearHashTable is simple. We start
at array entry t[i] where \(\texttt{i}=\texttt{hash(x)}\) and search entries t[i],
\(\texttt{t}[(\texttt{i}+1)\bmod \texttt{t.length}]\), \(\texttt{t}[(\texttt{i}+2)\bmod \texttt{t.length}]\), and so on,
until we find an index i' such that, either, t[i']=x, or t[i']=null.
In the former case we return t[i']. In the latter case, we conclude
that x is not contained in the hash table and return null.
T find(T x) {
int i = hash(x);
while (t[i] != null) {
if (t[i] != del && x.equals(t[i])) return t[i];
i = (i == t.length-1) ? 0 : i + 1; // increment i
}
return null;
}
The add(x) operation is also fairly easy to implement. After checking
that x is not already stored in the table (using find(x)), we search
t[i], \(\texttt{t}[(\texttt{i}+1)\bmod \texttt{t.length}]\), \(\texttt{t}[(\texttt{i}+2)\bmod \texttt{t.length}]\),
and so on, until we find a null or del and store x at that location,
increment n, and q, if appropriate.
boolean add(T x) {
if (find(x) != null) return false;
if (2*(q+1) > t.length) resize(); // max 50% occupancy
int i = hash(x);
while (t[i] != null && t[i] != del)
i = (i == t.length-1) ? 0 : i + 1; // increment i
if (t[i] == null) q++;
n++;
t[i] = x;
return true;
}
By now, the implementation of the remove(x) operation should be obvious.
We search t[i], \(\texttt{t}[(\texttt{i}+1)\bmod \texttt{t.length}]\), \(\texttt{t}[(\texttt{i}+2)\bmod
\texttt{t.length}]\), and so on until we find an index i' such that t[i']=x
or t[i']=null. In the former case, we set t[i']=del and return
true. In the latter case we conclude that x was not stored in the
table (and therefore cannot be deleted) and return false.
T remove(T x) {
int i = hash(x);
while (t[i] != null) {
T y = t[i];
if (y != del && x.equals(y)) {
t[i] = del;
n--;
if (8*n < t.length) resize(); // min 12.5% occupancy
return y;
}
i = (i == t.length-1) ? 0 : i + 1; // increment i
}
return null;
}
The correctness of the find(x), add(x), and remove(x) methods is
easy to verify, though it relies on the use of del values. Notice
that none of these operations ever sets a non-null entry to null.
Therefore, when we reach an index i' such that t[i']=null, this is
a proof that the element, x, that we are searching for is not stored
in the table; t[i'] has always been null, so there is no reason that
a previous add(x) operation would have proceeded beyond index i'.
The resize() method is called by add(x) when the number of non-null
entries exceeds \(\texttt{t.length}/2\) or by remove(x) when the number of
data entries is less than t.length/8. The resize() method works
like the resize() methods in other array-based data structures.
We find the smallest non-negative integer d such that \(2^{\texttt{d}}
\ge 3\texttt{n}\). We reallocate the array t so that it has size \(2^{\texttt{d}}\),
and then we insert all the elements in the old version of t into the
newly-resized copy of t. While doing this, we reset q equal to n
since the newly-allocated t contains no del values.
void resize() {
d = 1;
while ((1<<d) < 3*n) d++;
T[] told = t;
t = f.newArray(1<<d);
q = n;
// insert everything from told
for (int k = 0; k < told.length; k++) {
if (told[k] != null && told[k] != del) {
int i = hash(told[k]);
while (t[i] != null)
i = (i == t.length-1) ? 0 : i + 1;
t[i] = told[k];
}
}
}
5.2.1 Analysis of Linear Probing
Notice that each operation, add(x), remove(x), or find(x), finishes
as soon as (or before) it discovers the first null entry in t.
The intuition behind the analysis of linear probing is that, since at
least half the elements in t are equal to null, an operation should
not take long to complete because it will very quickly come across a
null entry. We shouldn't rely too heavily on this intuition, though,
because it would lead us to (the incorrect) conclusion that the expected
number of locations in t examined by an operation is at most 2.
For the rest of this section, we will assume that all hash values are
independently and uniformly distributed in \(\{0,\ldots,\texttt{t.length}-1\}\).
This is not a realistic assumption, but it will make it possible for
us to analyze linear probing. Later in this section we will describe a
method, called tabulation hashing, that produces a hash function that is
“good enough” for linear probing. We will also assume that all indices
into the positions of t are taken modulo t.length, so that t[i]
is really a shorthand for \(\texttt{t}[\texttt{i}\bmod\texttt{t.length}]\).
We say that a run of length \(k\) that starts at i occurs when all
the table entries \(\texttt{t[i]}, \texttt{t[i+1]},\ldots,\texttt{t}[\texttt{i}+k-1]\) are non-null
and \(\texttt{t}[\texttt{i}-1]=\texttt{t}[\texttt{i}+k]=\texttt{null}\). The number of non-null elements of
t is exactly q and the add(x) method ensures that, at all times,
\(\texttt{q}\le\texttt{t.length}/2\). There are q elements \(\texttt{x}_1,\ldots,\texttt{x}_{\texttt{q}}\)
that have been inserted into t since the last resize() operation.
By our assumption, each of these has a hash value, \(\texttt{hash}(\texttt{x}_j)\),
that is uniform and independent of the rest. With this setup, we can
prove the main lemma required to analyze linear probing.
i is \(O(c^k)\) for some constant \(0
i, then there are exactly \(k\)
elements \(\texttt{x}_j\) such that \(\texttt{hash}(\texttt{x}_j)\in\{\texttt{i},\ldots,\texttt{i}+k-1\}\).
The probability that this occurs is exactly
\begin{equation*}
p_k = \binom{\texttt{q}}{k}\left(\frac{k}{\texttt{t.length}}\right)^k\left(\frac{\texttt{t.length}-k}{\texttt{t.length}}\right)^{\texttt{q}-k} \enspace ,
\end{equation*}
since, for each choice of \(k\) elements, these \(k\) elements must hash to
one of the \(k\) locations and the remaining \(\texttt{q}-k\) elements must hash to
the other \(\texttt{t.length}-k\) table locations.11Note that \(p_k\) is greater
than the probability that a run of length \(k\) starts at i, since the definition of \(p_k\) does not include the requirement \(\texttt{t}[\texttt{i}-1]=\texttt{t}[\texttt{i}+k]=\texttt{null}\).
In the following derivation we will cheat a little and replace \(r!\) with \((r/e)^r\). Stirling's Approximation (Section 1.3.2) shows that this is only a factor of \(O(\sqrt{r})\) from the truth. This is just done to make the derivation simpler; Exercise 5.4 asks the reader to redo the calculation more rigorously using Stirling's Approximation in its entirety.
The value of \(p_k\) is maximized when t.length is minimum, and the data
structure maintains the invariant that \(\texttt{t.length} \ge 2\texttt{q}\), so
\begin{align*}
p_k & \le \binom{\texttt{q}}{k}\left(\frac{k}{2\texttt{q}}\right)^k\left(\frac{2\texttt{q}-k}{2\texttt{q}}\right)^{\texttt{q}-k} \\
& = \left(\frac{\texttt{q}!}{(\texttt{q}-k)!k!}\right)\left(\frac{k}{2\texttt{q}}\right)^k\left(\frac{2\texttt{q}-k}{2\texttt{q}}\right)^{\texttt{q}-k} \\
& \approx \left(\frac{\texttt{q}^{\texttt{q}}}{(\texttt{q}-k)^{\texttt{q}-k}k^k}\right)\left(\frac{k}{2\texttt{q}}\right)^k\left(\frac{2\texttt{q}-k}{2\texttt{q}}\right)^{\texttt{q}-k} && \text{[Stirling's approximation]} \\
& = \left(\frac{\texttt{q}^{k}\texttt{q}^{\texttt{q}-k}}{(\texttt{q}-k)^{\texttt{q}-k}k^k}\right)\left(\frac{k}{2\texttt{q}}\right)^k\left(\frac{2\texttt{q}-k}{2\texttt{q}}\right)^{\texttt{q}-k} \\
& = \left(\frac{\texttt{q}k}{2\texttt{q}k}\right)^k
\left(\frac{\texttt{q}(2\texttt{q}-k)}{2\texttt{q}(\texttt{q}-k)}\right)^{\texttt{q}-k} \\
& = \left(\frac{1}{2}\right)^k
\left(\frac{(2\texttt{q}-k)}{2(\texttt{q}-k)}\right)^{\texttt{q}-k} \\
& = \left(\frac{1}{2}\right)^k
\left(1+\frac{k}{2(\texttt{q}-k)}\right)^{\texttt{q}-k} \\
& \le \left(\frac{\sqrt{e}}{2}\right)^k \enspace .
\end{align*}
(In the last step, we use the inequality \((1+1/x)^x \le e\), which holds
for all \(x>0\).) Since \(\sqrt{e}/{2}< 0.824360636 < 1\), this completes
the proof.
Using Lemma 5.4 to prove upper-bounds on the expected
running time of find(x), add(x), and remove(x) is now fairly
straightforward. Consider the simplest case, where we execute
find(x) for some value x that has never been stored in the
LinearHashTable. In this case, \(\texttt{i}=\texttt{hash(x)}\) is a random value in
\(\{0,\ldots,\texttt{t.length}-1\}\) independent of the contents of t. If i
is part of a run of length \(k\), then the time it takes to execute the
find(x) operation is at most \(O(1+k)\). Thus, the expected running time
can be upper-bounded by
\begin{equation*}
O\left(1 + \left(\frac{1}{\texttt{t.length}}\right)\sum_{i=1}^{\texttt{t.length}}\sum_{k=0}^{\infty} k\Pr\{\text{\texttt{i} is part of a run of length \(k\)}\}\right) \enspace .
\end{equation*}
Note that each run of length \(k\) contributes to the inner sum \(k\) times for a total contribution of \(k^2\), so the above sum can be rewritten as
\begin{align*}
& { } O\left(1 + \left(\frac{1}{\texttt{t.length}}\right)\sum_{i=1}^{\texttt{t.length}}\sum_{k=0}^{\infty} k^2\Pr\{\mbox{\texttt{i} starts a run of length \(k\)}\}\right) \\
& \le O\left(1 + \left(\frac{1}{\texttt{t.length}}\right)\sum_{i=1}^{\texttt{t.length}}\sum_{k=0}^{\infty} k^2p_k\right) \\
& = O\left(1 + \sum_{k=0}^{\infty} k^2p_k\right) \\
& = O\left(1 + \sum_{k=0}^{\infty} k^2\cdot O(c^k)\right) \\
& = O(1) \enspace .
\end{align*}
The last step in this derivation comes from the fact that
\(\sum_{k=0}^{\infty} k^2\cdot O(c^k)\) is an exponentially decreasing
series.12In the terminology of many calculus texts, this sum
passes the ratio test: There exists a positive integer \(k_0\) such
that, for all \(k\ge k_0\), \(\frac{(k+1)^2c^{k+1}}{k^2c^k} < 1\).
Therefore, we conclude that the expected running time of the find(x) operation
for a value x that is not contained in a LinearHashTable is \(O(1)\).
If we ignore the cost of the resize() operation, then the above
analysis gives us all we need to analyze the cost of operations on a
LinearHashTable.
First of all, the analysis of find(x) given above applies to the
add(x) operation when x is not contained in the table. To analyze
the find(x) operation when x is contained in the table, we need only
note that this is the same as the cost of the add(x) operation that
previously added x to the table. Finally, the cost of a remove(x)
operation is the same as the cost of a find(x) operation.
In summary, if we ignore the cost of calls to resize(), all operations
on a LinearHashTable run in \(O(1)\) expected time. Accounting for the
cost of resize can be done using the same type of amortized analysis
performed for the ArrayStack data structure in Section 2.1.
5.2.2 Summary
The following theorem summarizes the performance of the LinearHashTable
data structure:
LinearHashTable implements the USet interface. Ignoring the
cost of calls to resize(), a LinearHashTable supports the operations
add(x), remove(x), and find(x) in \(O(1)\) expected time per
operation.
Furthermore, beginning with an empty LinearHashTable, any
sequence of \(m\) add(x) and remove(x) operations results in a total
of \(O(m)\) time spent during all calls to resize().
5.2.3 Tabulation Hashing
While analyzing the LinearHashTable structure, we made a very strong
assumption: That for any set of elements, \(\{\texttt{x}_1,\ldots,\texttt{x}_\texttt{n}\}\),
the hash values \(\texttt{hash}(\)x\(_1),\ldots,\texttt{hash}(\texttt{x}_\texttt{n})\) are independently and
uniformly distributed over the set \(\{0,\ldots,\texttt{t.length}-1\}\). One way to
achieve this is to store a giant array, tab, of length \(2^{\texttt{w}}\),
where each entry is a random w-bit integer, independent of all the
other entries. In this way, we could implement hash(x) by extracting
a d-bit integer from tab[x.hashCode()]:
int idealHash(T x) {
return tab[x.hashCode() >>> w-d];
}
Unfortunately, storing an array of size \(2^{\texttt{w}}\) is prohibitive in terms
of memory usage. The approach used by tabulation hashing is to,
instead, treat w-bit integers as being comprised of \(\texttt{w}/\texttt{r}\)
integers, each having only \(\texttt{r}\) bits. In this way, tabulation hashing
only needs \(\texttt{w}/\texttt{r}\) arrays each of length \(2^{\texttt{r}}\). All the entries
in these arrays are independent random w-bit integers. To obtain the value
of hash(x) we split x.hashCode() up into \(\texttt{w}/\texttt{r}\) r-bit integers
and use these as indices into these arrays. We then combine all these
values with the bitwise exclusive-or operator to obtain hash(x).
The following code shows how this works when \(\texttt{w}=32\) and \(\texttt{r}=4\):
int hash(T x) {
int h = x.hashCode();
return (tab[0][h&0xff]
^ tab[1][(h>>>8)&0xff]
^ tab[2][(h>>>16)&0xff]
^ tab[3][(h>>>24)&0xff])
>>> (w-d);
}
tab is a two-dimensional array with four columns and
\(2^{32/4}=256\) rows.
One can easily verify that, for any x, hash(x) is uniformly
distributed over \(\{0,\ldots,2^{\texttt{d}}-1\}\). With a little work, one
can even verify that any pair of values have independent hash values.
This implies tabulation hashing could be used in place of multiplicative
hashing for the ChainedHashTable implementation.
However, it is not true that any set of n distinct values gives a set
of n independent hash values. Nevertheless, when tabulation hashing is
used, the bound of Theorem 5.2 still holds. References for
this are provided at the end of this chapter.
5.3 Hash Codes
The hash tables discussed in the previous section are used to associate
data with integer keys consisting of w bits. In many cases, we
have keys that are not integers. They may be strings, objects, arrays,
or other compound structures. To use hash tables for these types of data,
we must map these data types to w-bit hash codes. Hash code mappings should
have the following properties:
- If
xandyare equal, thenx.hashCode()andy.hashCode()are equal. - If
xandyare not equal, then the probability that \(\texttt{x.hashCode()}=\texttt{y.hashCode()}\) should be small (close to \(1/2^{\texttt{w}}\)).
The first property ensures that if we store x in a hash table and later
look up a value y equal to x, then we will find x—as we should.
The second property minimizes the loss from converting our objects
to integers. It ensures that unequal objects usually have different
hash codes and so are likely to be stored at different locations in
our hash table.
5.3.1 Hash Codes for Primitive Data Types
Small primitive data types like char, byte, int, and float are
usually easy to find hash codes for. These data types always have a
binary representation and this binary representation usually consists of
w or fewer bits. (For example, in Java, byte is an 8-bit
type and float is a 32-bit type.) In these
cases, we just treat these bits as the representation of an integer in
the range \(\{0,\ldots,2^\texttt{w}-1\}\). If two values are different, they get
different hash codes. If they are the same, they get the same hash code.
A few primitive data types are made up of more than w bits, usually
\(c\texttt{w}\) bits for some constant integer \(c\). (Java's long and double
types are examples of this with \(c=2\).) These data types can be treated
as compound objects made of \(c\) parts, as described in the next section.
5.3.2 Hash Codes for Compound Objects
For a compound object, we want to create a hash code by combining the
individual hash codes of the object's constituent parts. This is not
as easy as it sounds. Although one can find many hacks for this (for
example, combining the hash codes with bitwise exclusive-or operations),
many of these hacks turn out to be easy to foil (see Exercises Exercise 5.7–Exercise 5.9).
However, if one is willing to do arithmetic with \(2\texttt{w}\) bits of
precision, then there are simple and robust methods available.
Suppose we have an object made up of several parts
\(P_0,\ldots,P_{r-1}\) whose hash codes are \(\texttt{x}_0,\ldots,\texttt{x}_{r-1}\).
Then we can choose mutually independent random w-bit integers
\(\texttt{z}_0,\ldots,\texttt{z}_{r-1}\) and a random \(2\texttt{w}\)-bit odd integer z and
compute a hash code for our object with
\begin{equation*}
h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) =
\left(\left(\texttt{z}\sum_{i=0}^{r-1} \texttt{z}_i \texttt{x}_i\right)\bmod 2^{2\texttt{w}}\right)
\ddiv 2^{\texttt{w}} \enspace .
\end{equation*}
Note that this hash code has a final step (multiplying by z and
dividing by \(2^{\texttt{w}}\)) that uses the multiplicative hash function
from Section 5.1.1 to take the \(2\texttt{w}\)-bit intermediate result and
reduce it to a w-bit final result. Here is an example of this method applied to a simple compound object with three parts x0, x1, and x2:
// ERROR: junk/Point3D.x0 not found
int hashCode() {
// random numbers from rand.org
long[] z = {0x2058cc50L, 0xcb19137eL, 0x2cb6b6fdL};
long zz = 0xbea0107e5067d19dL;
// convert (unsigned) hashcodes to long
long h0 = x0.hashCode() & ((1L<<32)-1);
long h1 = x1.hashCode() & ((1L<<32)-1);
long h2 = x2.hashCode() & ((1L<<32)-1);
return (int)(((z[0]*h0 + z[1]*h1 + z[2]*h2)*zz)
>>> 32);
}
w bit integers in \(\{0,\ldots,2^{\texttt{w}}-1\}\) and assume \(\texttt{x}_i \neq \texttt{y}_i\) for at least one index \(i\in\{0,\ldots,r-1\}\). Then
\begin{equation*}
\Pr\{ h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) = h(\texttt{y}_0,\ldots,\texttt{y}_{r-1}) \}
\le 3/2^{\texttt{w}} \enspace .
\end{equation*}
The final step of the hash function is to apply multiplicative hashing
to reduce our \(2\texttt{w}\)-bit intermediate result \(h'(\texttt{x}_0,\ldots,\texttt{x}_{r-1})\) to
a w-bit final result \(h(\texttt{x}_0,\ldots,\texttt{x}_{r-1})\). By Theorem 5.3,
if \(h'(\texttt{x}_0,\ldots,\texttt{x}_{r-1})\neq h'(\texttt{y}_0,\ldots,\texttt{y}_{r-1})\), then
\(\Pr\{h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) = h(\texttt{y}_0,\ldots,\texttt{y}_{r-1})\} \le 2/2^{\texttt{w}}\).
To summarize,
\begin{align*}
& \Pr\left\{\begin{array}
h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) \\
\quad = h(\texttt{y}_0,\ldots,\texttt{y}_{r-1})\end{array}\right\} \\
&= \Pr\left\{\begin{array}
\mbox{\(h'(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) = h'(\texttt{y}_0,\ldots,\texttt{y}_{r-1})\) or} \\
\mbox{\(h'(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) \neq h'(\texttt{y}_0,\ldots,\texttt{y}_{r-1})\)} \\
\quad \mbox{and
\(\texttt{z}h'(\texttt{x}_0,\ldots,\texttt{x}_{r-1})\ddiv2^{\texttt{w}} = \texttt{z} h'(\texttt{y}_0,\ldots,\texttt{y}_{r-1})\ddiv 2^{\texttt{w}}\)}
\end{array}\right\} \\
&\le 1/2^{\texttt{w}} + 2/2^{\texttt{w}} = 3/2^{\texttt{w}} \enspace .
\end{align*}
5.3.3 Hash Codes for Arrays and Strings
The method from the previous section works well for objects that have a
fixed, constant, number of components. However, it breaks down when we
want to use it with objects that have a variable number of components,
since it requires a random w-bit integer \(\texttt{z}_i\) for each component.
We could use a pseudorandom sequence to generate as many \(\texttt{z}_i\)'s as we
need, but then the \(\texttt{z}_i\)'s are not mutually independent, and it becomes
difficult to prove that the pseudorandom numbers don't interact badly
with the hash function we are using. In particular, the values of \(t\)
and \(\texttt{z}_i\) in the proof of Theorem 5.3 are no longer independent.
A more rigorous approach is to base our hash codes on polynomials over
prime fields; these are just regular polynomials that are evaluated
modulo some prime number, p. This method is based on the following
theorem, which says that polynomials over prime fields behave pretty-much
like usual polynomials:
To use Theorem 5.4, we hash a sequence of integers \(\texttt{x}_0,\ldots,\texttt{x}_{r-1}\) with each \(\texttt{x}_i\in \{0,\ldots,\texttt{p}-2\}\) using a random integer \(\texttt{z}\in\{0,\ldots,\texttt{p}-1\}\) via the formula \begin{equation*} h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) = \left(\texttt{x}_0\texttt{z}^0+\cdots+\texttt{x}_{r-1}\texttt{z}^{r-1}+(\texttt{p}-1)\texttt{z}^r \right)\bmod \texttt{p} \enspace . \end{equation*}
Note the extra \((\texttt{p}-1)\texttt{z}^r\) term at the end of the formula. It helps to think of \((\texttt{p}-1)\) as the last element, \(\texttt{x}_r\), in the sequence \(\texttt{x}_0,\ldots,\texttt{x}_{r}\). Note that this element differs from every other element in the sequence (each of which is in the set \(\{0,\ldots,\texttt{p}-2\}\)). We can think of \(\texttt{p}-1\) as an end-of-sequence marker.
The following theorem, which considers the case of two sequences of
the same length, shows that this hash function gives a good return for
the small amount of randomization needed to choose z:
w-bit integers in
\(\{0,\ldots,2^{\texttt{w}}-1\}\), and assume \(\texttt{x}_i \neq \texttt{y}_i\) for at least
one index \(i\in\{0,\ldots,r-1\}\). Then
\begin{equation*}
\Pr\{ h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) = h(\texttt{y}_0,\ldots,\texttt{y}_{r-1}) \}
\le (r-1)/\texttt{p} \enspace .
\end{equation*}
z.
The probability that we pick z to be one of these solutions is therefore
at most \((r-1)/\texttt{p}\).
Note that this hash function also deals with the case in which two sequences have different lengths, even when one of the sequences is a prefix of the other. This is because this function effectively hashes the infinite sequence \begin{equation*} \texttt{x}_0,\ldots,\texttt{x}_{r-1}, \texttt{p}-1,0,0,\ldots \enspace . \end{equation*} This guarantees that if we have two sequences of length \(r\) and \(r'\) with \(r > r'\), then these two sequences differ at index \(i=r\). In this case, Equation 5.6 becomes \begin{equation*} \left( \sum_{i=0}^{i=r'-1}(\texttt{x}_i-\texttt{y}_i)\texttt{z}^i + (\texttt{x}_{r'} - \texttt{p} + 1)\texttt{z}^{r'} +\sum_{i=r'+1}^{i=r-1}\texttt{x}_i\texttt{z}^i + (\texttt{p}-1)\texttt{z}^{r} \right)\bmod \texttt{p} = 0 \enspace , \end{equation*} which, by Theorem 5.4, has at most \(r\) solutions in \(\texttt{z}\). This combined with Theorem 5.5 suffice to prove the following more general theorem:
w-bit integers in
\(\{0,\ldots,2^{\texttt{w}}-1\}\). Then
\begin{equation*}
\Pr\{ h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) = h(\texttt{y}_0,\ldots,\texttt{y}_{r-1}) \}
\le \max\{r,r'\}/\texttt{p} \enspace .
\end{equation*}
The following example code shows how this hash function is applied to
an object that contains an array, x, of values:
int hashCode() {
long p = (1L<<32)-5; // prime: 2^32 - 5
long z = 0x64b6055aL; // 32 bits from random.org
int z2 = 0x5067d19d; // random odd 32 bit number
long s = 0;
long zi = 1;
for (int i = 0; i < x.length; i++) {
// reduce to 31 bits
long xi = (x[i].hashCode() * z2) >>> 1;
s = (s + zi * xi) % p;
zi = (zi * z) % p;
}
s = (s + zi * (p-1)) % p;
return (int)s;
}
The preceding code sacrifices some collision probability for implementation
convenience. In particular, it applies the multiplicative hash function
from Section 5.1.1, with \(\texttt{d}=31\) to reduce x[i].hashCode() to a
31-bit value. This is so that the additions and multiplications that are
done modulo the prime \(\texttt{p}=2^{32}-5\) can be carried out using unsigned
63-bit arithmetic. Thus the probability of two different sequences,
the longer of which has length \(r\), having the same hash code is at most
\begin{equation*}
2/2^{31} + r/(2^{32}-5)
\end{equation*}
rather than the \(r/(2^{32}-5)\) specified in Theorem 5.6.
5.4 Discussion and Exercises
Hash tables and hash codes represent an enormous and active field of research that is just touched upon in this chapter. The online Bibliography on Hashing [10] contains nearly 2000 entries.
A variety of different hash table implementations exist. The one
described in Section 5.1 is known as hashing with chaining
(each array entry contains a chain (List) of elements). Hashing with
chaining dates back to an internal IBM memorandum authored by H. P. Luhn
and dated January 1953. This memorandum also seems to be one of the
earliest references to linked lists.
An alternative to hashing with chaining is that used by open
addressing schemes, where all data is stored directly in an
array. These schemes include the LinearHashTable structure of
Section 5.2. This idea was also proposed, independently, by
a group at IBM in the 1950s. Open addressing schemes must deal with the
problem of collision resolution:
the case where two values hash
to the same array location. Different strategies exist for collision
resolution; these provide different performance guarantees and often
require more sophisticated hash functions than the ones described here.
Yet another category of hash table implementations are the so-called
perfect hashing methods.
These are methods in which find(x)
operations take \(O(1)\) time in the worst-case. For static data sets,
this can be accomplished by finding perfect hash functions
for
the data; these are functions that map each piece of data to a unique
array location. For data that changes over time, perfect hashing
methods include FKS two-level hash tables
[31,24]
and cuckoo hashing [57].
The hash functions presented in this chapter are probably among the most practical methods currently known that can be proven to work well for any set of data. Other provably good methods date back to the pioneering work of Carter and Wegman who introduced the notion of universal hashing and described several hash functions for different scenarios [14]. Tabulation hashing, described in Section 5.2.3, is due to Carter and Wegman [14], but its analysis, when applied to linear probing (and several other hash table schemes) is due to Pătraşcu and Thorup [60].
The idea of multiplicative hashing
is very old and seems to be
part of the hashing folklore [48]. However, the
idea of choosing the multiplier z to be a random odd number,
and the analysis in Section 5.1.1 is due to Dietzfelbinger et al [23]. This version of multiplicative hashing is one of the
simplest, but its collision probability of \(2/2^{\texttt{d}}\) is a factor of two
larger than what one could expect with a random function from \(2^{\texttt{w}}\to
2^{\texttt{d}}\). The multiply-add hashing
method uses the function
\begin{equation*}
h(\texttt{x}) = ((\texttt{z}\texttt{x} + b) \bmod 2^{\texttt{2w}}) \ddiv 2^{\texttt{2w}-\texttt{d}}
\end{equation*}
where z and b are each randomly chosen from \(\{0,\ldots,2^{\texttt{2w}}-1\}\).
Multiply-add hashing has a collision probability of only \(1/2^{\texttt{d}}\)
[21], but requires \(2\texttt{w}\)-bit precision arithmetic.
There are a number of methods of obtaining hash codes from fixed-length
sequences of w-bit integers. One particularly fast method
[11] is the function
\begin{equation*}\begin{array}
h(\texttt{x}_0,\ldots,\texttt{x}_{r-1}) \\
\quad = \left(\sum_{i=0}^{r/2-1} ((\texttt{x}_{2i}+\texttt{a}_{2i})\bmod 2^{\texttt{w}})((\texttt{x}_{2i+1}+\texttt{a}_{2i+1})\bmod 2^{\texttt{w}})\right) \bmod 2^{2\texttt{w}}
\end{array}
\end{equation*}
where \(r\) is even and \(\texttt{a}_0,\ldots,\texttt{a}_{r-1}\) are randomly chosen from
\(\{0,\ldots,2^{\texttt{w}}\}\). This yields a \(2\texttt{w}\)-bit hash code that has
collision probability \(1/2^{\texttt{w}}\). This can be reduced to a w-bit hash
code using multiplicative (or multiply-add) hashing. This method is fast
because it requires only \(r/2\) \(2\texttt{w}\)-bit multiplications whereas the
method described in Section 5.3.2 requires \(r\) multiplications.
(The \(\bmod\) operations occur implicitly by using w and \(2\texttt{w}\)-bit
arithmetic for the additions and multiplications, respectively.)
The method from Section 5.3.3 of using polynomials over prime fields
to hash variable-length arrays and strings is due to Dietzfelbinger et al [22]. Due to its use of the \(\bmod\) operator which relies
on a costly machine instruction, it is, unfortunately, not very fast.
Some variants of this method choose the prime p to be one of the form
\(2^{\texttt{w}}-1\), in which case the \(\bmod\) operator can be replaced with
addition (+) and bitwise-and (\&) operations [47].
Another option is to apply one of the fast methods for fixed-length
strings to blocks of length \(c\) for some constant \(c>1\) and then apply
the prime field method to the resulting sequence of \(\lceil r/c\rceil\)
hash codes.
- Show that, for any choice
of the muliplier,
z, there existsnvalues that all have the same hash code. (Hint: This is easy, and doesn't require any number theory.) - Given the multiplier,
z, describenvalues that all have the same hash code. (Hint: This is harder, and requires some basic number theory.)
x to a LinearHashTable, which simply stores x in the
first null array entry it finds. Explain why this could be very slow
by giving an example of a sequence of \(O(\texttt{n})\) add(x), remove(x),
and find(x) operations that would take on the order of \(\texttt{n}^2\)
time to execute.
boolean addSlow(T x) {
if (2*(q+1) > t.length) resize(); // max 50% occupancy
int i = hash(x);
while (t[i] != null) {
if (t[i] != del && x.equals(t[i])) return false;
i = (i == t.length-1) ? 0 : i + 1; // increment i
}
t[i] = x;
n++; q++;
return true;
}
hashCode() method for the String class
worked by not using all of the characters found in long strings. For
example, for a sixteen character string, the hash code was computed
using only the eight even-indexed characters. Explain why this was a
very bad idea by giving an example of large set of strings that all
have the same hash code.
w-bit integers, x and y.
Show why \(\texttt{x}\oplus\texttt{y}\) does not make a good hash code for your object.
Give an example of a large set of objects that would all have hash
code 0.
w-bit integers, x and y.
Show why \(\texttt{x}+\texttt{y}\) does not make a good hash code for your object.
Give an example of a large set of objects that would all have the same
hash code.
w-bit integers, x
and y. Suppose that the hash code for your object is defined
by some deterministic function \(h(\texttt{x},\texttt{y})\) that produces a single
w-bit integer. Prove that there exists a large set of objects that
have the same hash code.
w. Explain why, for a
positive integer \(x\)
\begin{equation*}
(x\bmod 2^{\texttt{w}}) + (x\ddiv 2^{\texttt{w}}) \equiv x \bmod (2^{\texttt{w}}-1) \enspace .
\end{equation*}
(This gives an algorithm for computing \(x \bmod (2^{\texttt{w}}-1)\) by
repeatedly setting
\begin{equation*}
\texttt{x = x\&((1<HashMap
or the HashTable or LinearHashTable implementations in this book,
and design a program that stores integers in this data
structure so that there are integers, x, such that find(x) takes
linear time. That is, find a set of n integers for which there are
\(c\texttt{n}\) elements that hash to the same table location.
Depending on how good the implementation is, you may be able to do this just by inspecting the code for the implementation, or you may have to write some code that does trial insertions and searches, timing how long it takes to add and find particular values. (This can be, and has been, used to launch denial of service attacks on web servers [17].)