Next: 3.3 : A Space-Efficient Up: 3. Linked Lists Previous: 3.1 : A Singly-Linked Contents
A
![]() (doubly-linked list) is very similar to an
(doubly-linked list) is very similar to an
![]() except
that each node
except
that each node
![]() in a
in a
![]() has references to both the node
has references to both the node
![]() that follows it and the node
that follows it and the node
![]() that precedes it.
that precedes it.
struct Node {
T x;
Node *prev, *next;
};
When implementing an
![]() , we saw that there were always some special
cases to worry about. For example, removing the last element from an
, we saw that there were always some special
cases to worry about. For example, removing the last element from an
![]() or adding an element to an empty
or adding an element to an empty
![]() requires special
care so that
requires special
care so that
![]() and
and
![]() are correctly updated. In a
are correctly updated. In a
![]() ,
the number of these special cases increases considerably. Perhaps the
cleanest way to take care of all these special cases in a
,
the number of these special cases increases considerably. Perhaps the
cleanest way to take care of all these special cases in a
![]() is to
introduce a
is to
introduce a
![]() node. This is a node that does not contain any data,
but acts as a placeholder so that there are no special nodes; every node
has both a
node. This is a node that does not contain any data,
but acts as a placeholder so that there are no special nodes; every node
has both a
![]() and a
and a
![]() , with
, with
![]() acting as the node that
follows the last node in the list and that precedes the first node in
the list. In this way, the nodes of the list are (doubly-)linked into
a cycle, as illustrated in Figure 3.2.
acting as the node that
follows the last node in the list and that precedes the first node in
the list. In this way, the nodes of the list are (doubly-)linked into
a cycle, as illustrated in Figure 3.2.
Node dummy;
int n;
DLList() {
dummy.next = &dummy;
dummy.prev = &dummy;
n = 0;
}
Finding the node with a particular index in a
![]() is easy; we can
either start at the head of the list (
is easy; we can
either start at the head of the list (
![]() ) and work forward,
or start at the tail of the list (
) and work forward,
or start at the tail of the list (
![]() ) and work backward.
This allows us to reach the
) and work backward.
This allows us to reach the
![]() th node in
th node in
![]() time:
time:
Node* getNode(int i) {
Node* p;
if (i < n / 2) {
p = dummy.next;
for (int j = 0; j < i; j++)
p = p->next;
} else {
p = &dummy;
for (int j = n; j > i; j--)
p = p->prev;
}
return (p);
}
The
![]() and
and
![]() operations are now also easy. We first find the
operations are now also easy. We first find the
![]() th node and then get or set its
th node and then get or set its
![]() value:
value:
T get(int i) {
return getNode(i)->x;
}
T set(int i, T x) {
Node* u = getNode(i);
T y = u->x;
u->x = x;
return y;
}
The running time of these operations is dominated by the time it takes
to find the
![]() th node, and is therefore
th node, and is therefore
![]() .
.
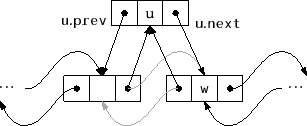
If we have a reference to a node
![]() in a
in a
![]() and we want to insert a
node
and we want to insert a
node
![]() before
before
![]() , then this is just a matter of setting
, then this is just a matter of setting
![]() ,
,
![]() , and then adjusting
, and then adjusting
![]() and
and
![]() . (See Figure 3.3.)
Thanks to the dummy node, there is no need to worry about
. (See Figure 3.3.)
Thanks to the dummy node, there is no need to worry about
![]() or
or
![]() not existing.
not existing.
Node* addBefore(Node *w, T x) {
Node *u = new Node;
u->x = x;
u->prev = w->prev;
u->next = w;
u->next->prev = u;
u->prev->next = u;
n++;
return u;
}
Now, the list operation
![]() is trivial to implement. We find the
is trivial to implement. We find the
![]() th node in the
th node in the
![]() and insert a new node
and insert a new node
![]() that contains
that contains
![]() just before it.
just before it.
void add(int i, T x) {
addBefore(getNode(i), x);
}
The only non-constant part of the running time of
![]() is the time
it takes to find the
is the time
it takes to find the
![]() th node (using
th node (using
![]() ). Thus,
). Thus,
![]() runs in
runs in
![]() time.
time.
Removing a node
![]() from a
from a
![]() is easy. We need only adjust pointers
at
is easy. We need only adjust pointers
at
![]() and
and
![]() so that they skip over
so that they skip over
![]() . Again, the use of the dummy node eliminates the need to consider any special cases:
. Again, the use of the dummy node eliminates the need to consider any special cases:
void remove(Node *w) {
w->prev->next = w->next;
w->next->prev = w->prev;
delete w;
n--;
}
Now the
![]() operation is trivial. We find the node with index
operation is trivial. We find the node with index
![]() and remove it:
and remove it:
T remove(int i) {
Node *w = getNode(i);
T x = w->x;
remove(w);
return x;
}
Again, the only expensive part of this operation is finding the
![]() th node
using
th node
using
![]() , so
, so
![]() runs in
runs in
![]() time.
time.
The following theorem summarizes the performance of a
![]() :
:
It is worth noting that, if we ignore the cost of the
![]() operation, then all operations on a
operation, then all operations on a
![]() take constant time.
Thus, the only expensive part of operations on a
take constant time.
Thus, the only expensive part of operations on a
![]() is finding
the relevant node. Once we have the relevant node, adding, removing,
or accessing the data at that node takes only constant time.
is finding
the relevant node. Once we have the relevant node, adding, removing,
or accessing the data at that node takes only constant time.
This is in sharp contrast to the array-based
![]() implementations of
Chapter 2; in those implementations, the relevant array
item can be found in constant time. However, addition or removal requires
shifting elements in the array and, in general, takes non-constant time.
implementations of
Chapter 2; in those implementations, the relevant array
item can be found in constant time. However, addition or removal requires
shifting elements in the array and, in general, takes non-constant time.
For this reason, linked list structures are well-suited to applications
where references to list nodes can be obtained through external means.
For example, pointers to the nodes of a linked list could be
stored in a
![]() . Then, to remove an item
. Then, to remove an item
![]() from the linked list,
the node that contains
from the linked list,
the node that contains
![]() can be found quickly using the
can be found quickly using the
![]() and
the node can be removed from the list in constant time.
and
the node can be removed from the list in constant time.
opendatastructures.org