Every computer science curriculum in the world includes a course on data
structures and algorithms. Data structures are that important;
they improve our quality of life and even save lives on a regular basis.
Many multi-million and several multi-billion dollar companies have been
built around data structures.
How can this be? If we think about it for even a few minutes, we
realize that we interact with data structures constantly.
- Open a file: File system data structures are used to locate
the parts of that file on disk so they can be retrieved. This isn't
easy; disks contain hundreds of millions of blocks. The contents of your
file could be stored on any one of them.
- Look up a contact on your phone: A data
structure is used to lookup a phone number based on partial
information even before you finish dialing/typing. This isn't
easy; your phone may contain information about a lot of
people--everyone you have ever had phone or email contact with--and
your phone doesn't have a very fast processor or a lot of memory.
- Login to your favourite social network: The network servers
use your login information look up your account information.
This isn't easy; the most popular social networks have hundreds of
millions of active users.
- Do a web search: The search engine uses data structures to find
the web pages containing your search terms. This isn't easy; there
are over 8.5 billion web pages on the Internet and each page contains
a lot of potential search terms.
- Phone emergency services (9-1-1): The emergency services network
looks up your phone number in a data structure that maps phone numbers
to addresses so that police cars, ambulances, or fire trucks can be
sent there without delay. This is important; the person making the
call may not be able to provide the exact address they are calling
from and a delay can mean the difference between life or death.
In the next section, we look at the operations supported by the most
commonly used data structures. Anyone with even a little bit of
programming experience will see that these operations are not hard to
implement correctly. We can store the data in an array or a linked list
and each operation can be implemented by iterating over all the elements
of the array or list and possibly adding or removing an element.
This kind of implementation is easy, but not very efficient. Does it
really matter? Computers are getting faster and faster. Maybe the
obvious implementation is good enough. Let's do some back-of-the-envelope
calculations to find out.
Imagine an application with a
moderately-sized data set, say of one million (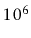 ), items. It is
reasonable, in most applications, to assume that the application will
want to look up each item at least once. This means we can expect to do
at least one million () lookups in this data. If each of these
lookups inspects each of the items, this gives a total
of
), items. It is
reasonable, in most applications, to assume that the application will
want to look up each item at least once. This means we can expect to do
at least one million () lookups in this data. If each of these
lookups inspects each of the items, this gives a total
of
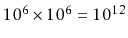 (one thousand billion) inspections.
(one thousand billion) inspections.
At the time of writing, even a very fast
desktop computer can not do more than one billion (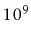 ) operations per
second.1.1This means that this application will take at least
) operations per
second.1.1This means that this application will take at least
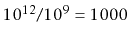 seconds, or roughly 16 minutes and 40 seconds. 16 minutes is an
eon in computer time, but a person might be willing to put up with it
(if they were headed out for a coffee break).
seconds, or roughly 16 minutes and 40 seconds. 16 minutes is an
eon in computer time, but a person might be willing to put up with it
(if they were headed out for a coffee break).
Now consider a company like Google, that
indexes over 8.5 billion web pages. By our calculations, doing any kind
of query over this data would take at least 8.5 seconds. We already
know that this isn't the case; web searches complete in much less than
8.5 seconds, and they do much more complicated queries than just asking
if a particular page is in their list of indexed pages. At the time
of writing, Google receives approximately 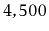 queries per second,
meaning that they would require at least
queries per second,
meaning that they would require at least
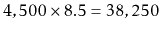 very
fast servers just to keep up.
very
fast servers just to keep up.
These examples tell us that the obvious implementations of data structures
do not scale well when the number of items,
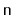 , in the data structure
and the number of operations,
, in the data structure
and the number of operations, 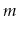 , performed on the data structure
are both large. In these cases, the time (measured in, say, machine
instructions) is roughly
, performed on the data structure
are both large. In these cases, the time (measured in, say, machine
instructions) is roughly
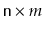 .
.
The solution, of course, is to carefully organize data within the data
structure so that not every operation requires inspecting every data item.
Although it sounds impossible at first, we will see data structures
where a search requires looking at only 2 items on average, independent
of the number of items stored in the data structure. In our billion
instruction per second computer it takes only
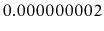 seconds to
search in a data structure containing a billion items (or a trillion,
or a quadrillion, or even a quintillion items).
seconds to
search in a data structure containing a billion items (or a trillion,
or a quadrillion, or even a quintillion items).
We will also see implementations of data structures that keep the
items in sorted order, where the number of items inspected during an
operation grows very slowly as a function of the number of items in
the data structure. For example, we can maintain a sorted set of one
billion items while inspecting at most 60 items during any operation.
In our billion instruction per second computer, these operations take
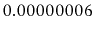 seconds each.
seconds each.
The remainder of this chapter briefly reviews some of the main concepts
used throughout the rest of the book. Section 1.1 describes
the interfaces implemented by all the data structures described in this
book and should be considered required reading. The remaining sections
discuss:
- some mathematical background including exponentials, logarithms,
factorials, asymptotic (big-Oh) notation, probability, and randomization;
- the model of computation;
- correctness, running time, and space;
- an overview of the rest of the chapters; and
- the sample code and typesetting conventions.
A reader with or without a background in these areas can easily skip
them now and come back to them later if necessary.
Footnotes
- ...
second.1.1
- Computer speeds are at most a few gigahertz (billions
of cycles per second) and each operation typically takes a few cycles.
Subsections
opendatastructures.org