Next: 4.3 : An Efficient Up: 4. Skiplists Previous: 4.1 The Basic Structure Contents
A
![]() uses a skiplist structure to implement the
uses a skiplist structure to implement the
![]() interface. When used this way, the list
interface. When used this way, the list ![]() stores the elements of
the
stores the elements of
the
![]() in sorted order. The
in sorted order. The
![]() method works by following
the search path for the smallest value
method works by following
the search path for the smallest value
![]() such that
such that
![]() :
:
Node* findPredNode(T x) {
Node *u = sentinel;
int r = h;
while (r >= 0) {
while ( u->next[r] != NULL && compare(u->next[r]->x, x) < 0)
u = u->next[r]; // go right in list r
r--; // go down into list r-1
}
return u;
}
T find(T x) {
Node *u = findPredNode(x);
return u->next[0] == NULL ? NULL : u->next[0]->x;
}
Following the search path for
![]() is easy: when situated at
some node,
is easy: when situated at
some node,
![]() , in
, in
![]() , we look right to
, we look right to
![]() .
If
.
If
![]() , then we take a step to the right in
, then we take a step to the right in
![]() ,
otherwise we move down into
,
otherwise we move down into
![]() . Each step (right or down) in
this search takes only constant time so, by Lemma 4.1,
the expected running time of
. Each step (right or down) in
this search takes only constant time so, by Lemma 4.1,
the expected running time of
![]() is
is
![]() .
.
Before we can add an element to a
![]() , we need a method to
simulate tossing coins to determine the height,
, we need a method to
simulate tossing coins to determine the height,
![]() , of a new node.
We do this by picking a random integer,
, of a new node.
We do this by picking a random integer,
![]() , and counting the number of
trailing
, and counting the number of
trailing ![]() s in the binary representation of
s in the binary representation of
![]() :1
:1
int pickHeight() {
int z = rand();
int k = 0;
int m = 1;
while ((z & m) != 0) {
k++;
m <<= 1;
}
return k;
}
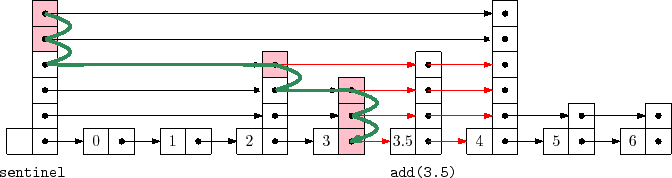
To implement the
![]() method in a
method in a
![]() we search for
we search for
![]() and then splice
and then splice
![]() into a few lists
into a few lists ![]() ,...,
,...,
![]() , where
, where
![]() is selected using the
is selected using the
![]() method. The easiest way to do this
is to use an array,
method. The easiest way to do this
is to use an array,
![]() , that keeps track of the nodes at which
the search path goes down from some list
, that keeps track of the nodes at which
the search path goes down from some list
![]() into
into
![]() .
More precisely,
.
More precisely,
![]() is the node in
is the node in
![]() where the search path
proceeded down into
where the search path
proceeded down into
![]() . The nodes that we modify to insert
. The nodes that we modify to insert
![]() are precisely the nodes
are precisely the nodes
![]() . The following
code implements this algorithm for
. The following
code implements this algorithm for
![]() :
:
bool add(T x) {
Node *u = sentinel;
int r = h;
int comp = 0;
while (r >= 0) {
while (u->next[r] != NULL && (comp = compare(u->next[r]->x, x)) < 0)
u = u->next[r];
if (u->next[r] != NULL && comp == 0)
return false;
stack[r--] = u; // going down, store u
}
Node *w = newNode(x, pickHeight());
while (h < w->height)
stack[++h] = sentinel; // increasing height of skiplist
for (int i = 0; i < w->height; i++) {
w->next[i] = stack[i]->next[i];
stack[i]->next[i] = w;
}
n++;
return true;
}
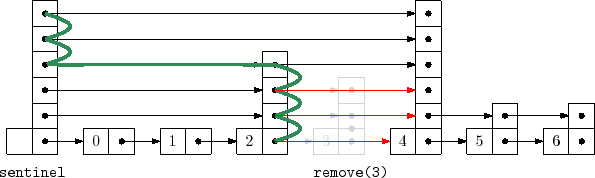
Removing an element,
![]() , is done in a similar way, except that there
is no need for
, is done in a similar way, except that there
is no need for
![]() to keep track of the search path. The removal
can be done as we are following the search path. We search for
to keep track of the search path. The removal
can be done as we are following the search path. We search for
![]() and each time the search moves downward from a node
and each time the search moves downward from a node
![]() , we check if
, we check if
![]() and if so, we splice
and if so, we splice
![]() out of the list:
out of the list:
bool remove(T x) {
bool removed = false;
Node *u = sentinel, *del;
int r = h;
int comp = 0;
while (r >= 0) {
while (u->next[r] != NULL && (comp = compare(u->next[r]->x, x)) < 0) {
u = u->next[r];
}
if (u->next[r] != NULL && comp == 0) {
removed = true;
del = u->next[r];
u->next[r] = u->next[r]->next[r];
if (u == sentinel && u->next[r] == NULL)
h--; // skiplist height has gone down
}
r--;
}
if (removed) {
delete del;
n--;
}
return removed;
}
The following theorem summarizes the performance of skiplists when used to implement sorted sets: