Next: 4.4 Analysis of Skiplists Up: 4. Skiplists Previous: 4.2 : An Efficient Contents
A
![]() implements the
implements the
![]() interface on top of a skiplist structure.
In a
interface on top of a skiplist structure.
In a
![]() ,
, ![]() contains the elements of the
list in the order they appear in the list. Just like with a
contains the elements of the
list in the order they appear in the list. Just like with a
![]() ,
elements can be added, removed, and accessed in
,
elements can be added, removed, and accessed in
![]() time.
time.
For this to be possible, we need a way to follow the search path for
the
![]() th element in
th element in ![]() . The easiest way to do this is to define
the notion of the length of an edge in some list,
. The easiest way to do this is to define
the notion of the length of an edge in some list,
![]() .
We define the length of every edge in
.
We define the length of every edge in ![]() as 1. The length of an edge,
as 1. The length of an edge,
![]() ,
in
,
in
![]() ,
,
![]() , is defined as the sum of the lengths of the edges below
, is defined as the sum of the lengths of the edges below
![]() in
in
![]() . Equivalently, the length of
. Equivalently, the length of
![]() is
the number of edges in
is
the number of edges in ![]() below
below
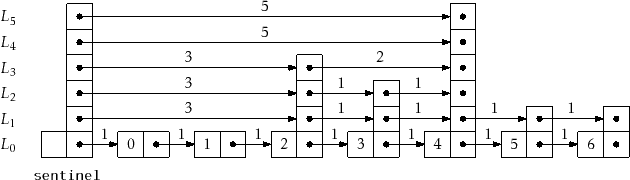
![]() . See Figure 4.5 for
an example of a skiplist with the lengths of its edges shown. Since the
edges of skiplists are stored in arrays, the lengths can be stored the same
way:
. See Figure 4.5 for
an example of a skiplist with the lengths of its edges shown. Since the
edges of skiplists are stored in arrays, the lengths can be stored the same
way:
struct Node {
T x;
int height; // length of next
int *length;
Node **next;
};
The useful property of this definition of length is that, if we are
currently at a node that is at position
![]() in
in ![]() and we follow an
edge of length
and we follow an
edge of length ![]() , then we move to a node whose position, in
, then we move to a node whose position, in ![]() ,
is
,
is
![]() . In this way, while following a search path, we can keep
track of the position,
. In this way, while following a search path, we can keep
track of the position,
![]() , of the current node in
, of the current node in ![]() . When at a
node,
. When at a
node,
![]() , in
, in
![]() , we go right if
, we go right if
![]() plus the length of the edge
plus the length of the edge
![]() is less than
is less than
![]() , otherwise we go
down into
, otherwise we go
down into
![]() .
.
Node* findPred(int i) {
Node *u = sentinel;
int r = h;
int j = -1; // the index of the current node in list 0
while (r >= 0) {
while (u->next[r] != NULL && j + u->length[r] < i) {
j += u->length[r];
u = u->next[r];
}
r--;
}
return u;
}
T get(int i) {
return findPred(i)->next[0]->x;
}
T set(int i, T x) {
Node *u = findPred(i)->next[0];
T y = u->x;
u->x = x;
return y;
}
Since the hardest part of the operations
![]() and
and
![]() is
finding the
is
finding the
![]() th node in
th node in ![]() , these operations run in
, these operations run in
![]() time.
time.
Adding an element to a
![]() at a position,
at a position,
![]() , is fairly
straightforward. Unlike in a
, is fairly
straightforward. Unlike in a
![]() , we are sure that a new
node will actually be added, so we can do the addition at the same time
as we search for the new node's location. We first pick the height,
, we are sure that a new
node will actually be added, so we can do the addition at the same time
as we search for the new node's location. We first pick the height,
![]() ,
of the newly inserted node,
,
of the newly inserted node,
![]() , and then follow the search path for
, and then follow the search path for
![]() .
Anytime the search path moves down from
.
Anytime the search path moves down from
![]() with
with
![]() , we
splice
, we
splice
![]() into
into
![]() . The only extra care needed is to ensure that
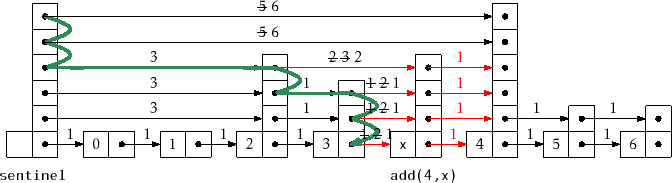
the lengths of edges are updated properly. See Figure 4.6.
. The only extra care needed is to ensure that
the lengths of edges are updated properly. See Figure 4.6.
Note that, each time the search path goes down at a node,
![]() , in
, in
![]() ,
the length of the edge
,
the length of the edge
![]() increases by one, since we are adding
an element below that edge at position
increases by one, since we are adding
an element below that edge at position
![]() . Splicing the node
. Splicing the node
![]() between two nodes,
between two nodes,
![]() and
and
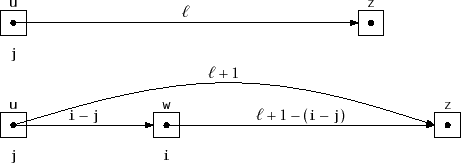
![]() , works as shown in Figure 4.7. While
following the search path we are already keeping track of the position,
, works as shown in Figure 4.7. While
following the search path we are already keeping track of the position,
![]() , of
, of
![]() in
in ![]() . Therefore, we know that the length of the edge from
. Therefore, we know that the length of the edge from
![]() to
to
![]() is
is
![]() . We can also deduce the length of the edge
from
. We can also deduce the length of the edge
from
![]() to
to
![]() from the length,
from the length, ![]() , of the edge from
, of the edge from
![]() to
to
![]() .
Therefore, we can splice in
.
Therefore, we can splice in
![]() and update the lengths of the edges in
constant time.
and update the lengths of the edges in
constant time.
This sounds more complicated than it actually is and the code is actually quite simple:
void add(int i, T x) {
Node *w = newNode(x, pickHeight());
if (w->height > h)
h = w->height;
add(i, w);
}
Node* add(int i, Node *w) {
Node *u = sentinel;
int k = w->height;
int r = h;
int j = -1; // index of u
while (r >= 0) {
while (u->next[r] != NULL && j + u->length[r] < i) {
j += u->length[r];
u = u->next[r];
}
u->length[r]++; // to account for new node in list 0
if (r <= k) {
w->next[r] = u->next[r];
u->next[r] = w;
w->length[r] = u->length[r] - (i - j);
u->length[r] = i - j;
}
r--;
}
n++;
return u;
}
By now, the implementation of
the
![]() operation in a
operation in a
![]() should be obvious. We follow the search path for the node at position
should be obvious. We follow the search path for the node at position
![]() . Each time the search path takes a step down from a node,
. Each time the search path takes a step down from a node,
![]() , at level
, at level
![]() we decrement the length of the edge leaving
we decrement the length of the edge leaving
![]() at that level. We also check if
at that level. We also check if
![]() is the element of rank
is the element of rank
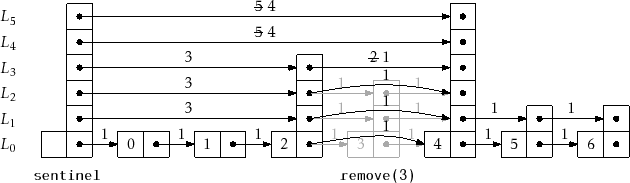
![]() and, if so, splice it out of the list at that level. An example is shown in Figure 4.8.
and, if so, splice it out of the list at that level. An example is shown in Figure 4.8.
T remove(int i) {
T x = NULL;
Node *u = sentinel, *del;
int r = h;
int j = -1; // index of node u
while (r >= 0) {
while (u->next[r] != NULL && j + u->length[r] < i) {
j += u->length[r];
u = u->next[r];
}
u->length[r]--; // for the node we are removing
if (j + u->length[r] + 1 == i && u->next[r] != NULL) {
x = u->next[r]->x;
u->length[r] += u->next[r]->length[r];
del = u->next[r];
u->next[r] = u->next[r]->next[r];
if (u == sentinel && u->next[r] == NULL)
h--;
}
r--;
}
deleteNode(del);
n--;
return x;
}
The following theorem summarizes the performance of the
![]() data structure:
data structure:
opendatastructures.org