Next: 3.4 Discussion and Exercises Up: 3. Linked Lists Previous: 3.2 DLList: A Doubly-Linked Contents Index
One of the drawbacks of linked lists (besides the time it takes to access elements that are deep within the list) is their space usage. Each node in a DLList requires an additional two references to the next and previous nodes in the list. Two of the fields in a Node are dedicated to maintaining the list, and only one of the fields is for storing data!
An SEList (space-efficient list) reduces this wasted space using
a simple idea: Rather than store individual elements in a DLList,
we store a block (array) containing several items. More precisely, an
SEList is parameterized by a block size
![]() . Each individual
node in an SEList stores a block that can hold up to
. Each individual
node in an SEList stores a block that can hold up to
![]() elements.
elements.
For reasons that will become clear later, it will be helpful if we can
do Deque operations on each block. The data structure that we choose
for this is a BDeque (bounded deque),
derived from the ArrayDeque
structure described in Section 2.4. The BDeque differs from the
ArrayDeque in one small way: When a new BDeque is created, the size
of the backing array
![]() is fixed at
is fixed at
![]() and never grows or shrinks.
The important property of a BDeque is that it allows for the addition
or removal of elements at either the front or back in constant time. This
will be useful as elements are shifted from one block to another.
and never grows or shrinks.
The important property of a BDeque is that it allows for the addition
or removal of elements at either the front or back in constant time. This
will be useful as elements are shifted from one block to another.
An SEList is just a doubly-linked list of blocks. In addition to
![]() and
and
![]() pointers, each node
pointers, each node
![]() in an SEList contains a BDeque,
in an SEList contains a BDeque,
![]() .
.
An SEList places very tight restrictions on the number of elements
in a block: Unless a block is the last block, then that block contains
at least
![]() and at most
and at most
![]() elements. This means that, if an
SEList contains
elements. This means that, if an
SEList contains
![]() elements, then it has at most
elements, then it has at most
The first challenge we face with an SEList is finding the list item
with a given index
![]() . Note that the location of an element consists
of two parts:
. Note that the location of an element consists
of two parts:
To find the block that contains a particular element, we proceed the same way as we do in a DLList. We either start at the front of the list and traverse in the forward direction, or at the back of the list and traverse backwards until we reach the node we want. The only difference is that, each time we move from one node to the next, we skip over a whole block of elements.

Remember that, with the exception of at most one block, each block
contains at least
![]() elements, so each step in our search gets
us
elements, so each step in our search gets
us
![]() elements closer to the element we are looking for. If we
are searching forward, this means that we reach the node we want after
elements closer to the element we are looking for. If we
are searching forward, this means that we reach the node we want after
![]() steps. If we search backwards, then we reach the node we
want after
steps. If we search backwards, then we reach the node we
want after
![]() steps. The algorithm takes the smaller
of these two quantities depending on the value of
steps. The algorithm takes the smaller
of these two quantities depending on the value of
![]() , so the time to
locate the item with index
, so the time to
locate the item with index
![]() is
is
![]() .
.
Once we know how to locate the item with index
![]() , the
, the
![]() and
and
![]() operations translate into getting or setting a particular
index in the correct block:
operations translate into getting or setting a particular
index in the correct block:

The running times of these operations are dominated by the time it takes
to locate the item, so they also run in
![]() time.
time.
Adding elements to an SEList is a little more complicated. Before
considering the general case, we consider the easier operation,
![]() ,
in which
,
in which
![]() is added to the end of the list. If the last block is full
(or does not exist because there are no blocks yet), then we first
allocate a new block and append it to the list of blocks. Now that
we are sure that the last block exists and is not full, we append
is added to the end of the list. If the last block is full
(or does not exist because there are no blocks yet), then we first
allocate a new block and append it to the list of blocks. Now that
we are sure that the last block exists and is not full, we append
![]() to the last block.
to the last block.

Things get more complicated when we add to the interior of the list
using
![]() . We first locate
. We first locate
![]() to get the node
to get the node
![]() whose block
contains the
whose block
contains the
![]() th list item. The problem is that we want to insert
th list item. The problem is that we want to insert
![]() into
into
![]() 's block, but we have to be prepared for the case where
's block, but we have to be prepared for the case where
![]() 's block already contains
's block already contains
![]() elements, so that it is full and
there is no room for
elements, so that it is full and
there is no room for
![]() .
.
Let
![]() denote
denote
![]() ,
,
![]() ,
,
![]() ,
and so on. We explore
,
and so on. We explore
![]() looking for a node
that can provide space for
looking for a node
that can provide space for
![]() . Three cases can occur during our
space exploration (see Figure 3.4):
. Three cases can occur during our
space exploration (see Figure 3.4):
|

The running time of the
![]() operation depends on which of
the three cases above occurs. Cases 1 and 2 involve examining and
shifting elements through at most
operation depends on which of
the three cases above occurs. Cases 1 and 2 involve examining and
shifting elements through at most
![]() blocks and take
blocks and take
![]() time.
Case 3 involves calling the
time.
Case 3 involves calling the
![]() method, which moves
method, which moves
![]() elements and takes
elements and takes
![]() time. If we ignore the cost of Case 3
(which we will account for later with amortization) this means that
the total running time to locate
time. If we ignore the cost of Case 3
(which we will account for later with amortization) this means that
the total running time to locate
![]() and perform the insertion of
and perform the insertion of
![]() is
is
![]() .
.
Removing an element from an SEList is similar to adding an element.
We first locate the node
![]() that contains the element with index
that contains the element with index
![]() .
Now, we have to be prepared for the case where we cannot remove an element
from
.
Now, we have to be prepared for the case where we cannot remove an element
from
![]() without causing
without causing
![]() 's block to become smaller than
's block to become smaller than
![]() .
.
Again, let
![]() denote
denote
![]() ,
,
![]() ,
,
![]() ,
and so on. We examine
,
and so on. We examine
![]() in order to look
for a node from which we can borrow an element to make the size of
in order to look
for a node from which we can borrow an element to make the size of
![]() 's block at least
's block at least
![]() . There are three cases to consider
(see Figure 3.5):
. There are three cases to consider
(see Figure 3.5):
|

Like the
![]() operation, the running time of the
operation, the running time of the
![]() operation is
operation is
![]() if we ignore the cost of
the
if we ignore the cost of
the
![]() method that occurs in Case 3.
method that occurs in Case 3.
Next, we consider the cost of the
![]() and
and
![]() methods
that may be executed by the
methods
that may be executed by the
![]() and
and
![]() methods. For the
sake of completeness, here they are:
methods. For the
sake of completeness, here they are:
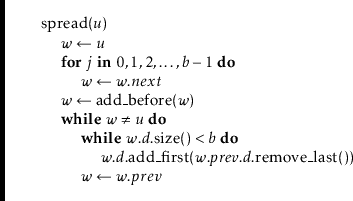

The running time of each of these methods is dominated by the two
nested loops. Both the inner and outer loops execute at most
![]() times, so the total running time of each of these methods
is
times, so the total running time of each of these methods
is
![]() . However, the following lemma shows that
these methods execute on at most one out of every
. However, the following lemma shows that
these methods execute on at most one out of every
![]() calls to
calls to
![]() or
or
![]() .
.
Notice that, if Case 1 occurs during the
![]() method, then
only one node,
method, then
only one node,
![]() has the size of its block changed. Therefore,
at most one node, namely
has the size of its block changed. Therefore,
at most one node, namely
![]() , goes from being rugged to being
fragile. If Case 2 occurs, then a new node is created, and this node
is fragile, but no other node changes size, so the number of fragile
nodes increases by one. Thus, in either Case 1 or Case 2 the potential
of the SEList increases by at most one.
, goes from being rugged to being
fragile. If Case 2 occurs, then a new node is created, and this node
is fragile, but no other node changes size, so the number of fragile
nodes increases by one. Thus, in either Case 1 or Case 2 the potential
of the SEList increases by at most one.
Finally, if Case 3 occurs, it is because
![]() are all fragile nodes. Then
are all fragile nodes. Then
![]() is called and these
is called and these
![]() fragile nodes are replaced with
fragile nodes are replaced with
![]() rugged nodes. Finally,
rugged nodes. Finally,
![]() is added to
is added to
![]() 's block, making
's block, making
![]() fragile. In total the
potential decreases by
fragile. In total the
potential decreases by
![]() .
.
In summary, the potential starts at 0 (there are no nodes in the list).
Each time Case 1 or Case 2 occurs, the potential increases by at
most 1. Each time Case 3 occurs, the potential decreases by
![]() .
The potential (which counts the number of fragile nodes) is never
less than 0. We conclude that, for every occurrence of Case 3, there
are at least
.
The potential (which counts the number of fragile nodes) is never
less than 0. We conclude that, for every occurrence of Case 3, there
are at least
![]() occurrences of Case 1 or Case 2. Thus, for every
call to
occurrences of Case 1 or Case 2. Thus, for every
call to
![]() there are at least
there are at least
![]() calls to
calls to
![]() . This
completes the proof.
. This
completes the proof.
![]()
The following theorem summarizes the performance of the SEList data structure:
The space (measured in words)3.1 used by an SEList
that stores
![]() elements is
elements is
![]() .
.
The SEList is a trade-off between an ArrayList and a DLList where
the relative mix of these two structures depends on the block size
![]() .
At the extreme
.
At the extreme
![]() , each SEList node stores at most three values,
which is not much different than a DLList. At the other extreme,
, each SEList node stores at most three values,
which is not much different than a DLList. At the other extreme,
![]() , all the elements are stored in a single array, just like in
an ArrayList. In between these two extremes lies a trade-off between
the time it takes to add or remove a list item and the time it takes to
locate a particular list item.
, all the elements are stored in a single array, just like in
an ArrayList. In between these two extremes lies a trade-off between
the time it takes to add or remove a list item and the time it takes to
locate a particular list item.
![\includegraphics[width=\textwidth ]{figs-python/selist-add-a}](img1305.png)
![\includegraphics[width=\textwidth ]{figs-python/selist-add-b}](img1306.png)
![\includegraphics[width=\textwidth ]{figs-python/selist-add-c}](img1307.png)
![\includegraphics[scale=0.90909]{figs-python/selist-remove-a}](img1351.png)
![\includegraphics[scale=0.90909]{figs-python/selist-remove-b}](img1352.png)
![\includegraphics[scale=0.90909]{figs-python/selist-remove-c}](img1353.png)