Next: 4.2 SkiplistSSet: An Efficient Up: 4. Skiplists Previous: 4. Skiplists Contents
Conceptually, a skiplist is a sequence of singly-linked lists
![]() , where each
, where each ![]() contains a subset of the items
in
contains a subset of the items
in ![]() . We start with the input list
. We start with the input list ![]() that contains
that contains
![]() items and construct
items and construct ![]() from
from ![]() ,
, ![]() from
from ![]() , and so on.
The items in
, and so on.
The items in ![]() are obtained by tossing a coin for each element,
are obtained by tossing a coin for each element,
![]() ,
in
,
in ![]() and including
and including
![]() in
in ![]() if the coin comes up heads.
This process ends when we create a list
if the coin comes up heads.
This process ends when we create a list ![]() that is empty. An example
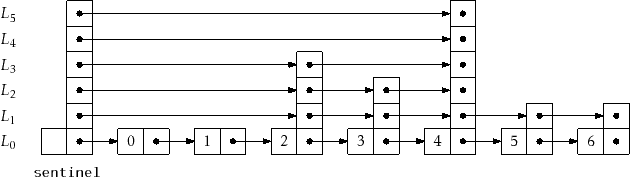
of a skiplist is shown in Figure 4.1.
that is empty. An example
of a skiplist is shown in Figure 4.1.
For an element,
![]() , in a skiplist, we call the height of
, in a skiplist, we call the height of
![]() the
largest value
the
largest value ![]() such that
such that
![]() appears in
appears in ![]() . Thus, for example,
elements that only appear in
. Thus, for example,
elements that only appear in ![]() have height 0. If we spend a few
moments thinking about it, we notice that the height of
have height 0. If we spend a few
moments thinking about it, we notice that the height of
![]() corresponds
to the following experiment: Toss a coin repeatedly until the first time
it comes up tails. How many times did it come up heads? The answer,
not surprisingly, is that the expected height of a node is 1. (We expect
to toss the coin twice before getting tails, but we don't count the last
toss.) The height of a skiplist is the height of its tallest node.
corresponds
to the following experiment: Toss a coin repeatedly until the first time
it comes up tails. How many times did it come up heads? The answer,
not surprisingly, is that the expected height of a node is 1. (We expect
to toss the coin twice before getting tails, but we don't count the last
toss.) The height of a skiplist is the height of its tallest node.
At the head of every list is a special node, called the sentinel,
that acts as a dummy node for the list. The key property of skiplists
is that there is a short path, called the search path, from the
sentinel in ![]() to every node in
to every node in ![]() . Remembering how to construct
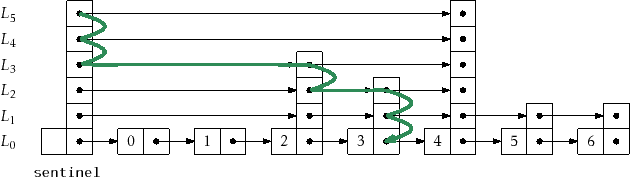
a search path for a node,
. Remembering how to construct
a search path for a node,
![]() , is easy (see Figure 4.2)
: Start at the top left corner of your skiplist (the sentinel in
, is easy (see Figure 4.2)
: Start at the top left corner of your skiplist (the sentinel in ![]() )
and always go right unless that would overshoot
)
and always go right unless that would overshoot
![]() , in which case you
should take a step down into the list below.
, in which case you
should take a step down into the list below.
More precisely, to construct the search path for the node
![]() in
in ![]() we start at the sentinel,
we start at the sentinel,
![]() , in
, in ![]() . Next, we examine
. Next, we examine
![]() .
If
.
If
![]() contains an item that appears before
contains an item that appears before
![]() in
in ![]() , then
we set
, then
we set
![]() . Otherwise, we move down and continue the search
at the occurrence of
. Otherwise, we move down and continue the search
at the occurrence of
![]() in the list
in the list ![]() . We continue this way
until we reach the predecessor of
. We continue this way
until we reach the predecessor of
![]() in
in ![]() .
.
The following result, which we will prove in Section 4.4, shows that the search path is quite short:
A space-efficient way to implement a Skiplist is to define a Node,
![]() , as consisting of a data value,
, as consisting of a data value,
![]() , and an array,
, and an array,
![]() , of
pointers, where
, of
pointers, where
![]() points to
points to
![]() 's successor in the list
's successor in the list
![]() . In this way, the data,
. In this way, the data,
![]() , in a node is
referenced
only once, even though
, in a node is
referenced
only once, even though
![]() may appear in several lists.
may appear in several lists.
class Node<T> {
T x;
Node<T>[] next;
Node(T ix, int h) {
x = ix;
next = (Node<T>[])Array.newInstance(Node.class, h+1);
}
int height() {
return next.length - 1;
}
}
The next two sections of this chapter discuss two different applications
of skiplists. In each of these applications, ![]() stores the main
structure (a list of elements or a sorted set of elements).
The primary difference between these structures is in how
a search path is navigated; in particular, they differ in how
they decide if a search path should go down into
stores the main
structure (a list of elements or a sorted set of elements).
The primary difference between these structures is in how
a search path is navigated; in particular, they differ in how
they decide if a search path should go down into ![]() or go right
within
or go right
within ![]() .
.
opendatastructures.org