Next: 7. Random Binary Search Up: 6. Binary Trees Previous: 6.2 : An Unbalanced Contents
Binary trees have been used to model relationships for literally thousands of years. One reason for this is that binary trees naturally model (pedigree) family trees. These are the family trees in which the root is a person, the left and right children are the person's parents, and so on, recursively. In more recent centuries binary trees have also been used to model species-trees in biology, where the leaves of the tree represent extant species and the internal nodes of the tree represent speciation events in which two populations of a single species evolve into two separate species.
Binary search trees appear to have been discovered independently by several groups in the 1950s [43, Section 6.2.2]. Further references to specific kinds of binary search trees are provided in subsequent chapters.
When implementing a binary tree from scratch, there are several design decisions to be made. One of these is the question of whether or not each node stores a pointer to its parent. If most of the operations simply follow a root-to-leaf path, then parent pointers are unnecessary, and are a potential source of coding errors. On the other hand, the lack of parent pointers means that tree traversals must be done recursively or with the use of an explicit stack. Some other methods (like inserting or deleting into some kinds of balanced binary search trees) are also complicated by the lack of parent pointers.
Another design decision is concerned with how to store the parent,
left child, and right child pointers at a node. In the implementation
given here, they are stored as separate variables. Another option is
to store them in an array,
![]() , of length 3, so that
, of length 3, so that
![]() is the
left child of
is the
left child of
![]() ,
,
![]() is the right child of
is the right child of
![]() , and
, and
![]() is the parent of
is the parent of
![]() . Using an array this way means that some sequences
of if statements can be simplified into algebraic expressions.
. Using an array this way means that some sequences
of if statements can be simplified into algebraic expressions.
An example of such a simplification occurs during tree traversal. If
a traversal arrives at a node
![]() from
from
![]() , then the next node in
the traversal is
, then the next node in
the traversal is
![]() . Similar examples occur when
there is left-right symmetry. For example, the sibling of
. Similar examples occur when
there is left-right symmetry. For example, the sibling of
![]() is
is
![]() . This works whether
. This works whether
![]() is a left child
(
is a left child
(
![]() ) or a right child (
) or a right child (
![]() ) of
) of
![]() . In some cases this means
that some complicated code that would otherwise need to have both a left
version and right version can be written only once. See the methods
. In some cases this means
that some complicated code that would otherwise need to have both a left
version and right version can be written only once. See the methods
![]() and
and
![]() on page
on page ![[*]](crossref.png) for an example.
for an example.
A pre-order traversal of a binary tree is a traversal that visits
each node,
![]() , before any of its children. An in-order traversal
visits
, before any of its children. An in-order traversal
visits
![]() after visiting all the nodes in
after visiting all the nodes in
![]() 's left subtree but before
visiting any of the nodes in
's left subtree but before
visiting any of the nodes in
![]() 's right subtree. A post-order
traversal visits
's right subtree. A post-order
traversal visits
![]() only after visiting all other nodes in
only after visiting all other nodes in
![]() 's subtree.
The pre/in/post-order numbering of a tree labels the nodes of a tree with
the integers
's subtree.
The pre/in/post-order numbering of a tree labels the nodes of a tree with
the integers
![]() in the order that they are encountered
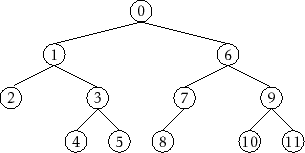
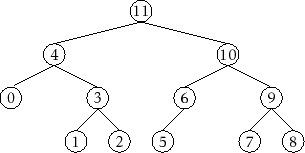
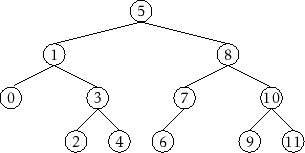
by a pre/in/post-order traversal. See Figure 6.10
for an example.
in the order that they are encountered
by a pre/in/post-order traversal. See Figure 6.10
for an example.
These values should be maintained, even during the
![]() and
and
![]() operations, but this should not increase the cost of these
operations by more than a constant factor.
operations, but this should not increase the cost of these
operations by more than a constant factor.